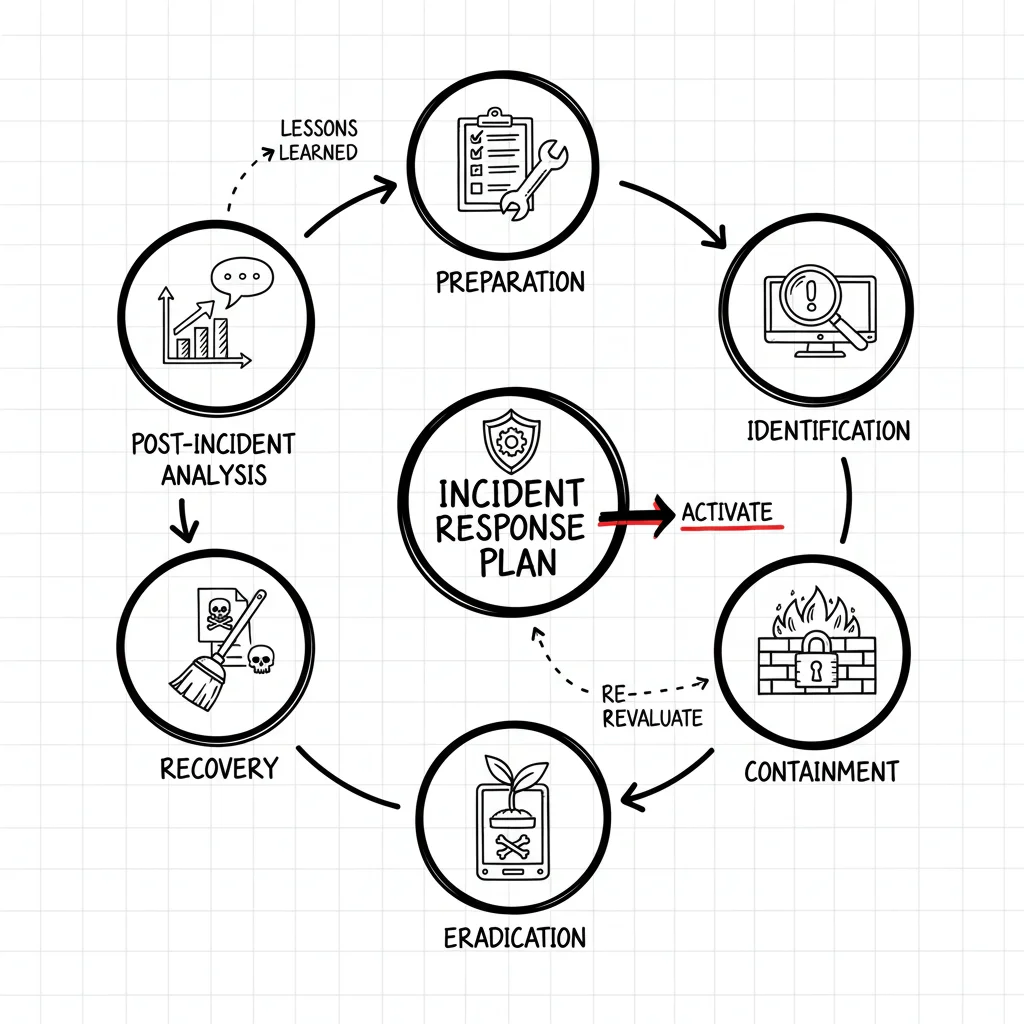
10 Essential Database Management Best Practices for 2025
Modern IT relies on the database as the central core of every operation. It acts as the primary engine powering critical applications, driving business intelligence, and supporting advanced analytics. Treating its upkeep as a secondary concern is a significant gamble. Neglect often leads to severe performance bottlenecks, serious security vulnerabilities, and irreversible data loss. The distinction between a reliable system and an operational liability lies in following established principles.
This guide moves beyond generic advice to present essential database management best practices. For IT professionals, developers, and certification candidates, mastering these strategies is fundamental. MindMesh Academy provides actionable insights, implementation steps, and real-world scenarios for immediate application. Our focus remains on the practical application of theory to solve real problems.
Experienced Database Administrators (DBAs), developers architecting data solutions, and IT professionals aiming for certifications need these concepts. This applies specifically to those pursuing the AWS Certified Database - Specialty, Microsoft Certified: Azure Database Administrator Associate, or CompTIA Data+. Understanding these methods is vital for anyone managing high-volume environments. This article provides clear insights into building and maintaining a resilient data infrastructure that scales with demand. We explore the specific techniques that differentiate high-performing systems from those that accumulate technical debt and operational friction. By following these steps, you can ensure your systems remain stable and efficient. Use these core practices to protect your most valuable digital asset: your data.
1. Database Normalization: Structuring for Integrity and Efficiency
Database normalization is a primary technique in relational database design, first introduced by Edgar F. Codd. This systematic process organizes data to minimize redundancy and protect data integrity. By organizing columns and tables, normalization ensures that data dependencies follow a logical structure. This helps your database stay flexible and scalable while preventing anomalies that can damage data during insertions, updates, or deletions.
The process follows progressive guidelines called normal forms. First (1NF), Second (2NF), and Third Normal Form (3NF) are the standard levels used in most environments. Each form expands on the previous one to reduce duplicate data and strengthen table relationships.
- 1NF: Each table cell must contain only one value, and the table must have a primary key.
- 2NF: The table must meet 1NF criteria, and every non-key attribute must fully depend on the primary key.
- 3NF: The table must meet 2NF criteria, and every non-key attribute must depend only on the primary key, avoiding dependencies on other non-key attributes (transitive dependency).
Normalization is a core element of database management. It prevents inconsistent data and makes long-term maintenance easier. Many certification exams for platforms like Microsoft Azure SQL Database or AWS RDS evaluate a candidate's ability to apply these principles.
Real-World Application and Benefits
Imagine an e-commerce platform that tracks customer orders. Without normalization, a single Orders table might repeat customer names and addresses alongside product names and prices for every purchase. This creates massive data duplication. Normalization separates this information into distinct tables: Customers, Products, and Orders. The Orders table then uses foreign keys to reference a CustomerID and ProductID. This approach removes the need to store the same text multiple times. If a customer changes their address, you update one record in the Customers table instead of hundreds of individual order rows. This method ensures data consistency while lowering storage requirements.
Actionable Implementation Tips
If you are preparing for data-centric IT roles, use these strategies to apply normalization effectively:
- Aim for Third Normal Form (3NF): Most transactional applications function best at 3NF. It provides a reliable balance between data integrity and query speed. It ensures all non-key attributes relate directly to the primary key.
- Utilize Database Design Tools: Applications like MySQL Workbench, pgAdmin, or cloud-based ERD designers help you visualize relationships. These tools make it easier to see dependencies and spot opportunities for better table structures.
- Document Your Schema Thoroughly: Keep clear records of your design choices. Explain why you chose a specific normal form and why you chose to denormalize certain areas. This documentation is vital for future maintenance and helps demonstrate your design logic during professional reviews.
- Strategically Consider Denormalization: Some systems, such as data warehouses or analytical databases, prioritize read speed over storage efficiency. In these cases, you might intentionally add redundant data back into the system. This reduces the number of joins needed for complex queries. Use this approach sparingly and only when you have measured the performance benefits against the risks to data integrity.
Reflection Prompt: How might a poorly normalized database complicate troubleshooting or data analysis in your current environment?
2. Regular Database Backups and Recovery Planning: Your Ultimate Safety Net
A reliable backup and recovery strategy serves as the final safety net for any database. This approach protects information and ensures business continuity when technical issues arise. The process involves more than simply copying files from one drive to another. It requires creating consistent, verifiable copies of database information and establishing tested procedures to restore operations quickly after hardware failures, human errors, security breaches, or unexpected natural disasters. This plan aims to minimize downtime and prevent data loss, protecting the most valuable digital assets of an organization.
A resilient strategy includes setting up automated backup schedules, verifying the integrity of those files, and storing copies in separate geographic locations. Modern database management requires a proactive mindset, treating backups as a non-negotiable part of daily work rather than a secondary task. For professional certifications such as the AWS Certified SysOps Administrator or the Azure Administrator Associate, you must understand specific backup types—including full, differential, and transaction log backups—along with various recovery procedures used in enterprise environments.
Real-World Application and Benefits
Financial firms offer a clear example of these principles in action. These organizations often use real-time replication and continuous monitoring to ensure they never lose transaction data. If a primary server fails, the system switches to a replica in seconds. Healthcare providers also follow these rules to comply with HIPAA regulations. These laws mandate encrypted backups and specific retention periods, keeping patient records secure and available for many years. These examples show that a strong recovery plan prevents catastrophic data loss and satisfies legal requirements while maintaining user trust through consistent uptime.
Actionable Implementation Tips
Use these strategies to build a resilient recovery plan. These concepts frequently appear on professional certification exams and represent the current standard for data protection:
- Adhere to the 3-2-1 Backup Rule: Keep at least three copies of your data. Use two different types of storage media. Store at least one copy in an offsite location. This method removes single points of failure and strengthens your disaster recovery stance against site-wide issues.
- Define and Document RTO and RPO: Set a Recovery Time Objective (RTO) to define how long the system can be down before the business suffers. Establish a Recovery Point Objective (RPO) to determine how much data loss is acceptable. These two metrics dictate how you design your technical infrastructure.
- Automate and Monitor Everything: Use software to manage backup schedules, verification checks, and monitoring alerts. Manual backups are unreliable and invite human error. Automation provides consistency and notifies your team immediately if a process fails. You can find details on automating operational tasks for AWS on MindMesh Academy.
- Test Recovery Procedures Regularly: A backup has no value if you cannot use it to restore data when a crisis occurs. Run disaster recovery drills every month or quarter. Simulate different failures to see if your team can meet the RTO and RPO targets. Regular testing exposes weaknesses before a real emergency happens.
Reflection Prompt: When was the last time your organization conducted a full recovery test? What challenges did you encounter?
3. Database Indexing Strategy: Accelerating Data Retrieval
Effective indexing is vital for optimizing query performance. It involves building specialized lookup structures that the database search engine uses to find data. This functions like an index in a book where you look up a term to find a page number rather than reading every page. A well-designed index reduces data retrieval time, making applications much more responsive. However, there are trade-offs: indexes require extra storage and create overhead during write operations like INSERT, UPDATE, and DELETE. This happens because the database must update the index every time the table data changes.
Success requires balancing read-speed gains against the costs of write-performance. Understanding index types—such as B-tree, hash, and full-text, along with the differences between clustered and non-clustered indexes—is a central part of database management best practices. This knowledge is standard across systems like Microsoft SQL Server, Oracle, and PostgreSQL. A strategic approach ensures that high-priority queries run with maximum efficiency. This directly affects user experience and is a core focus area for those seeking the Microsoft Certified: Azure Database Administrator Associate credential.
Real-World Application and Benefits
Imagine a social media platform where users search for posts by a specific username or a trending hashtag. Without indexes, the database would perform a full table scan, checking every single post to find matches. On a table containing billions of records, this operation is slow and uses heavy system resources. It might take minutes to return results. By creating indexes on columns like user_id and hashtag, the database engine locates relevant posts almost immediately. Search performance can shift from minutes to mere milliseconds. This change improves platform scalability and makes the interface feel fast and reliable for the end user.
Actionable Implementation Tips
To develop a reliable indexing strategy—a skill often tested in performance-focused certifications—use these guidelines:
- Analyze Query Patterns: Identify columns used in
WHEREclauses,JOINconditions,ORDER BYclauses, andGROUP BYclauses. These are primary candidates for indexing. Fast lookups on these fields provide the most noticeable performance improvements for your application. - Monitor Execution Plans: Use database tools such as
EXPLAINin PostgreSQL and MySQL,EXPLAIN PLANin Oracle, or the Query Store and Execution Plan features in SQL Server. These tools show how the engine executes a query. Use them to find slow queries, detect bottlenecks, and see if the engine uses your indexes or defaults to a scan. - Avoid Over-Indexing: While indexes help, too many will slow down write performance and waste storage. Review your setup regularly. Delete unused or duplicate indexes to keep the database efficient. Focus on index quality rather than quantity to prevent the database from performing unnecessary background tasks during updates.
- Use Covering Indexes: If a query only needs a few columns, a covering index can include all that data within the index itself. This allows the database to retrieve all information directly from the index. It skips the step of looking up the main table entirely, which accelerates data retrieval for those specific requests.
Reflection Prompt: Think about a slow query you've encountered. How might an index have improved its performance, and what trade-offs would that introduce?
4. Database Security and Access Control: Shielding Your Most Valuable Asset
Database security includes the broad measures used to protect sensitive information from unauthorized access, corruption, and malicious attacks. It requires a multi-layered strategy that features authentication methods, granular access controls, data encryption for files in transit and at rest, and constant monitoring. Because of increasing cyber threats and strict privacy laws, securing a database moves from a technical chore to a vital business necessity. This ensures that data remains confidential, accurate, and accessible to those who need it.

Applying these security measures ensures that only authorized users or software can interact with specific data sets. This involves a mix of policies and technologies that align with standards taught in certifications such as CompTIA Security+ or CISSP, and security tracks from AWS and Azure. Correct implementation safeguards trade secrets and customer data, including Personally Identifiable Information (PII). It also secures financial records for PCI DSS compliance and helps organizations meet the requirements of laws like GDPR and HIPAA.
Real-World Application and Benefits
Consider a healthcare provider managing millions of patient records. The system must enforce HIPAA-compliant access controls so a physician views only their own patients, while a billing clerk only sees financial entries. This is usually handled via Role-Based Access Control (RBAC), where permissions connect to job roles rather than specific people. Similarly, banks use end-to-end encryption to protect transactions in transit using TLS/SSL and at rest via Transparent Data Encryption (TDE). This prevents data theft even if someone physically accesses the storage hardware. Such measures are vital for staying compliant and keeping customer trust.
Actionable Implementation Tips
To effectively implement strong database security, which is a critical skill for any IT professional, follow these key strategies:
- Implement the Principle of Least Privilege (PoLP): Give users and applications the minimum permissions required for their specific tasks. No user, including a database administrator, should have default, wide-ranging access to all tables. Review these permissions monthly and remove any that are no longer needed.
- Utilize Database Firewalls and Monitoring: Setup a Web Application Firewall (WAF) or a dedicated Database Firewall to identify and block harmful SQL queries. Monitor database activity logs daily to spot and react to unusual login patterns or access attempts immediately.
- Keep Software and Patches Updated: Update your Database Management System (DBMS) regularly, whether you use SQL Server, Oracle, PostgreSQL, or MySQL. Apply security patches as soon as they are released to close vulnerabilities that attackers often target. Use automation to keep these systems current.
- Conduct Periodic Security Audits and Penetration Testing: Schedule independent security audits and penetration tests to find and repair security gaps before they are exploited. This proactive strategy is a highly effective way to harden your environment against external threats.
Reflection Prompt: How can you verify that the principle of least privilege is truly being followed for all users and applications accessing your critical databases?
5. Performance Monitoring and Query Optimization: Driving Peak Efficiency
Performance monitoring and query optimization represent a continuous cycle of tracking database metrics, identifying bottlenecks, and refining SQL queries. The goal is to keep the system running at top speed. This process involves using tools to observe server health and analyze query execution plans. By doing this, you address issues before they ever reach the end-user or hurt business operations. This practice is vital for maintaining a responsive application, especially as data volume and user load grow over time.
Effective tuning is a central part of database management. It has a direct effect on user experience and the cost of running your infrastructure. If you regularly review how your database handles requests, you can avoid buying expensive hardware upgrades just to keep up. It ensures your applications remain competitive and meet service level agreements (SLAs). Proficiency in this area is a core competency for certifications like the AWS Certified Data Engineer – Associate or the Azure Data Engineer Associate.
Real-World Application and Benefits
Look at a platform like LinkedIn. It manages millions of concurrent requests for profile views and feed updates. Without constant monitoring, slow queries would quickly ruin the user experience and cause people to leave the platform. By studying logs and tuning SQL statements, LinkedIn keeps data retrieval times in the millisecond range. Uber operates similarly. Their ride-matching systems need real-time database optimization to link drivers and riders without delay. Low latency is a requirement for their business model and for keeping customers satisfied.
Actionable Implementation Tips
To monitor database performance and optimize queries, use these strategies:
- Set Up Automated Alerts and Baselines: Use monitoring tools such as AWS CloudWatch, Azure Monitor, Datadog, or New Relic. Start by establishing baseline metrics for CPU usage, I/O operations, and query latency. Then, configure automated alerts to notify your team when these metrics cross specific thresholds. This allows you to handle problems before they lead to outages.
- Regularly Review and Analyze Slow Queries: Most database systems can log slow queries. Set a schedule to review these logs and find inefficient SQL. When you find a slow query, look at the execution plan. This helps you see if the database is missing an index or if it is performing a costly full table scan.
- Use Database-Specific Optimization Tools: Most database engines include tools for this work. Use PostgreSQL's
EXPLAIN ANALYZEto see how queries run. In SQL Server, use the Query Store and the Database Engine Tuning Advisor. Oracle users can rely on AWR or ASH reports. These built-in advisors give you clear steps to improve performance without guessing. - Implement Strategic Query Caching: If your data rarely changes, use an in-memory cache like Redis or Memcached. This reduces the number of times your application has to talk to the database. Caching takes the weight off your database server and makes the application feel much faster to the end-user.
Reflection Prompt: If your application suddenly became slow, what three performance metrics would you check first, and why?
6. Data Lifecycle Management: Governing Data from Creation to Archival
DLM serves as a policy-driven system for managing information throughout its entire existence. It tracks data from its initial creation or acquisition through to its final archival or secure deletion. This framework handles data according to its changing business value, which usually fluctuates as the information ages. Proper DLM ensures that data stays on the right storage tier based on performance needs and cost constraints. It forces organizations to keep data only as long as compliance rules or business requirements demand. When the information is no longer needed, it is removed using secure methods.
The data lifecycle involves several distinct phases: creation, storage, active usage, sharing, backup, archiving, and destruction. By applying automated policies to each phase, organizations can improve database performance by keeping active records on the fastest disks. Meanwhile, they can control storage expenses by shifting older records to cheaper, high-capacity hardware. This method satisfies strict regulatory mandates like GDPR, HIPAA, and PCI DSS. A solid DLM plan is a core part of modern database management best practices. It balances data accessibility with security and budget efficiency. These concepts are central to certifications like ITIL Foundation, which focuses on structured service management, and cloud architecture tracks that teach storage tiering, such as AWS S3 lifecycle policies or Azure Blob storage tiers.
Real-World Application and Benefits
In the healthcare sector, patient medical records provide a clear example. These files are updated frequently and accessed often during active treatment. After a period of inactivity—perhaps 2 to 5 years post-treatment—the facility must still retain the records to comply with HIPAA regulations. Rather than keeping this data on expensive, high-speed primary storage, the system moves the files to an archival tier like tape backups or cold cloud storage. Once the legally mandated retention period expires, which may take decades, the data is destroyed irrevocably. This tiered strategy maintains fast access for active patients while cutting costs on historical files. It also protects the organization from legal or financial penalties caused by poor data handling.
Actionable Implementation Tips
To effectively implement data lifecycle management, focus on integrating these strategies into your data governance framework:
- Develop Clear Data Retention and Classification Policies: Work with legal, compliance, and business teams to categorize data by type, sensitivity, and business value. Set specific retention windows for every data class, such as financial logs, customer PII, or application telemetry. These windows guide the data through its lifecycle.
- Implement Automated Workflows and Tiering: Use database features like partitioning or archival tables to manage data movement. Cloud-native tools such as AWS S3 lifecycle rules or Azure Storage tiers automate the transition between storage layers. For instance, you can set a rule to move transactional records older than two years to a cheaper object storage system automatically.
- Regularly Audit and Review DLM Practices: Check your retention, archival, and disposal routines frequently. This ensures your team follows the rules and remains compliant as new laws appear. Audits help identify gaps and inefficiencies in how the organization handles its data.
- Utilize Storage Optimization Techniques for Archived Data: When sending data to an archival tier, apply compression and deduplication. These methods shrink the physical storage footprint and lower monthly bills. Make sure the archival format remains readable and the storage method stays stable so you can retrieve data if an audit or legal request arrives.
Reflection Prompt: How might your current data retention policies impact storage costs and query performance for historical data?
7. Database Change Management and Version Control: Taming the Evolution of Data Schemas
Database change management is the systematic process for tracking, controlling, and deploying modifications to a database schema, stored procedures, functions, and configurations. This discipline ensures that every alteration is documented, tested, and formally approved before rolling out to production environments. By treating database code and schema definitions with the same rigor as application code, you prevent inconsistencies and maintain data integrity. It also stabilizes system performance across development, staging, and production environments.
Modern change management integrates the database into CI/CD (Continuous Integration/Continuous Delivery) pipelines, making deployments repeatable and auditable. Without these controls, manual changes—often called "schema drift"—can lead to deployment failures, data corruption, or downtime. Using version control for your database, similar to Git for application code, is a core database management best practice. It transforms a chaotic process into a predictable, automated workflow. This skill set is highly valued by professionals pursuing DevOps and database administration certifications.
Real-World Application and Benefits
Large software companies like Atlassian manage database updates for products like Jira and Confluence using specialized tools such as Flyway or Liquibase. When a developer needs to alter the database—for instance, by adding a column or modifying an index—they create a new, versioned SQL migration script. This script is committed to a Git repository alongside the application code. This process ensures that when the application is deployed, the database migrates automatically and consistently to the correct version. It eliminates manual errors, prevents deployment mismatches, and provides a clear audit trail of how the schema has evolved over time.
Actionable Implementation Tips
To manage database changes and apply version control effectively, follow these strategic guidelines for IT operations:
- Adopt Database Migration Tools: Use migration frameworks like Flyway, Liquibase, or cloud services such as AWS Database Migration Service. These tools automate the tracking of schema changes, ensuring every environment runs the correct version. They also provide specific rollback capabilities if a deployment fails.
- Enforce Script-Based Changes (Database as Code): Prohibit direct, ad-hoc changes to the production database using GUI tools. All modifications (DDL and DML) must be captured in version-controlled SQL scripts. This "database as code" approach creates an auditable history of every change, facilitates peer review, and ensures consistency across the team.
- Test Thoroughly in Staging Environments: Before a production deployment, all migration scripts must be rigorously tested in a staging environment. This environment should mirror production in terms of data volume and schema structure. Testing helps identify data integrity issues, performance regressions, or compatibility problems early in the cycle. To learn more about this setup, check out the guide on automating operational tasks on MindMesh Academy.
- Maintain Versioning Branches Aligned with Application Code: Align your database schema versions with your application code branches. Using Git for database scripts allows teams to manage different database states for features in development, testing, and production. It prevents conflicts and ensures that the application and its database are always compatible during the release cycle.
Reflection Prompt: How might a "database as code" approach improve collaboration and reduce errors in your team's development workflow?
8. Database Documentation and Standards: The Foundation of Maintainability
Database documentation and strict adherence to established standards are the foundation of a maintainable and scalable data environment. This practice involves creating a set of rules and records that describe your database structure, business logic, and operational procedures. It goes beyond basic schema diagrams. You must include naming conventions, data dictionaries, clear data lineage, and process documentation. This approach guarantees that technical knowledge stays accessible to the whole team rather than being trapped in the mind of one developer or DBA. When a senior member leaves, the team should not struggle to understand why a specific table exists or how a trigger functions.
Effective records act as a central reference. They help developers, administrators, analysts, and auditors understand data context and interdependencies. Clear standards reduce confusion and help new team members start productive work faster. This discipline is a vital part of professional database management. It prevents the growth of confusing systems that build up technical debt and slow down development. These practices also align with ITIL knowledge management principles, which emphasize that information must be discoverable and accurate to support service delivery.
Real-World Application and Benefits
Consider how a large financial institution handles strict regulatory audits. Documentation details every table’s purpose and column definitions like data types or constraints. It also tracks the specific business rules for data transformations. When auditors check how a financial report is created or how a compliance metric is calculated, the team uses these records to trace data from the source to the final result. This shows compliance and builds trust with regulators. Without these standards, an audit request might cause a slow, manual investigation that leads to fines or reputational damage. Reliable records turn a potential crisis into a routine task.
Actionable Implementation Tips
To build better documentation and standards, integrate these strategies into your daily workflow:
- Establish and Enforce Naming Conventions: Use a consistent and logical system for naming tables, columns, indexes, and stored procedures. Examples include
tbl_Customersfor tables,pk_CustomerIDfor primary keys, andusp_GetOrderByIDfor stored procedures. Enforce these rules through automated linters or mandatory code reviews to ensure consistency across every department. - Use Automated Documentation Tools: Tools like Dataedo, Redgate SQL Doc, or Doxygen for stored functions can generate documentation directly from your database schema. This reduces manual work and keeps your records updated whenever the schema changes. Automation helps prevent the documentation from becoming obsolete as soon as a new script is executed.
- Maintain a Centralized Data Dictionary: Create a dictionary that explains every table and column in detail. Include data types, default values, and the business context that justifies why the data is collected. Use platforms like Atlassian Confluence, SharePoint, or dedicated data catalog software to host this information so the team can find it easily.
- Include Documentation in Change Management: Make updates a required part of the database deployment process. No schema change or new procedure should go live unless its documentation is updated at the same time. This keeps your records accurate and current for everyone involved, preventing future troubleshooting delays.
Reflection Prompt: How much time could your team save if every database object had clear, up-to-date documentation?
9. Database Scalability Planning: Preparing for Growth and Peak Performance
Database scalability planning is the proactive process of designing a database architecture to handle growth in data volume, user traffic, and transaction complexity without losing performance. It involves predicting future demands and implementing strategies that allow a system to expand or shrink capacity efficiently. This practice is essential for modern database management. It ensures applications remain fast and cost-effective as the user base grows.
The two primary approaches to scaling are vertical and horizontal. Vertical scaling involves adding more hardware power—like CPU, RAM, or faster storage—to an existing server. Horizontal scaling, which is the standard for cloud environments, distributes the workload across many smaller servers or instances. Effective scalability planning uses a hybrid approach, combining techniques like sharding, clustering, replication, and load balancing to build high-performing infrastructure. This foresight prevents costly, reactive overhauls when a system hits its hardware limits. These concepts are foundational for AWS and Azure architects and database specialists.
Real-World Application and Benefits
Consider Netflix, which handles billions of requests daily. They use a polyglot persistence strategy, choosing different database types optimized for specific tasks. For example, they use Apache Cassandra for viewing history because it scales well across many nodes. For transactional systems where data consistency is the highest priority, they use relational databases. This distributed, purpose-built architecture allows the company to spread data and processing across hundreds or thousands of servers. Cloud-native services like AWS Aurora, with its read replicas and global databases, or Azure Cosmos DB, with automatic partitioning, show how planning for horizontal scaling from the start supports massive growth and disaster recovery.
Actionable Implementation Tips
To plan for database scalability, integrate these strategies into your design process. These skills are rigorously tested in cloud certification exams:
- Plan for Scale from Day One: Do not treat scalability as an afterthought. During initial design, consider how data will be partitioned and replicated, even if you start with a single instance. This mindset saves significant work later when you need to refactor code or change the underlying architecture to meet new demand.
- Implement Read Replicas for Read-Heavy Workloads: If your application has a high read-to-write ratio, use read replicas. This technique offloads read queries to separate database instances, leaving the primary database available for write operations. This improves overall throughput and query speed. Cloud providers like AWS RDS and Azure SQL Database offer managed read replica services to simplify this.
- Use Caching Strategies: Implement a caching layer using in-memory data stores like Redis or Memcached. Caching frequently accessed data in memory reduces the number of queries hitting the database disk. This lowers latency and decreases the total load on your database server, leading to a better user experience and lower hardware costs.
- Embrace Sharding for Horizontal Growth: When a single server is no longer sufficient for your data volume or transaction rate, partition your data across multiple databases, known as shards. Each shard operates independently, allowing your application to scale horizontally by adding more servers as needed. This strategy is used by large-scale platforms like Facebook to manage billions of active users.
Reflection Prompt: If your application suddenly experiences a 10x increase in users, what scalability strategy would you implement first, and why?
10. Data Quality Management and Validation: Ensuring Trustworthy Information
Data quality management is an all-encompassing discipline focused on building processes and using tools to ensure data remains accurate, complete, consistent, and timely. This practice goes further than basic error checking. It builds a culture of data excellence where teams trust information for every decision they make. By applying strict validation rules, running regular cleansing routines, and setting clear data governance policies, you can prevent the "garbage in, garbage out" cycle that weakens many systems and undermines trust.
High-quality data is the essential base for reliable analytics, daily business operations, and strategic planning. Poor data leads to flawed insights, compliance risks, financial losses, and damaged customer trust. Integrating active quality checks into your database management best practices is more than an IT chore; it is a vital business function that protects your most valuable information assets. This is a primary focus for project managers—the PMP certification highlights data quality for project success—and data professionals in every field.
Real-World Application and Benefits
Look at a healthcare organization where accurate patient data is mandatory for treatment, billing, and meeting HIPAA regulations. A strong data quality program ensures that patient records include full medical histories, current contact information, and accurate insurance details. This active strategy helps prevent dangerous medical errors, such as incorrect medication dosages, and cuts down on claim rejections and administrative costs. It also ensures the organization meets health information rules without delay. In a retail setting, clean and consistent product catalog data ensures a smooth customer experience and accurate inventory management, which prevents shipping errors and keeps customers satisfied.
Actionable Implementation Tips
To manage and validate your data quality effectively, use these strategic approaches:
- Implement Validation at the Point of Entry: The most efficient way to keep data clean is to block bad data before it enters the database. Use application-level checks, database constraints like
NOT NULL,CHECKconstraints, or foreign keys, and triggers to enforce rules for format and consistency as data is created or updated. - Establish and Monitor Data Quality Metrics: You cannot improve what you do not track. Define key performance indicators (KPIs) for data quality, such as completeness (the percentage of filled fields), accuracy (correct values compared to a known source), and timeliness (how fresh the data is). Check these metrics often and use dashboards to see trends and find areas that need work.
- Use Data Profiling Tools: Use specialized profiling and quality tools like Informatica Data Quality, Talend, or cloud-native services to scan your datasets. These tools find anomalies, missing values, and patterns automatically. This gives you a clear view of your current data status and helps you decide which cleansing tasks to handle first.
- Create Dedicated Data Stewardship Roles: Assign specific data domains to individuals or teams called data stewards. These professionals define data standards, fix identified quality issues, and oversee cleansing projects to ensure data remains fit for its intended purpose. This creates a clear line of accountability for the state and reliability of the information.
Reflection Prompt: How might inaccurate customer data impact your organization's sales, marketing efforts, or customer satisfaction?
Database Management Best Practices Comparison
| Aspect | Database Normalization | Regular Database Backups & Recovery Planning | Database Indexing Strategy | Database Security & Access Control | Performance Monitoring & Query Optimization | Data Lifecycle Management |
|---|---|---|---|---|---|---|
| Implementation Complexity 🔄 | Moderate to high complexity. It requires specific design expertise and strict adherence to several normal forms. | Moderate. It involves setting automated schedules, configuring reliable backups, and running regular recovery tests. | Moderate. Success requires a clear understanding of index types, query patterns, and technical trade-offs. | High. This requires implementing strong security policies, data encryption, and granular access controls for all users. | High. It demands specialized knowledge for continuous tuning and using monitoring tools for real-time tracking. | Moderate to high. Requires careful policy planning and managing data across multiple storage stages and tiers. |
| Resource Requirements ⚡ | Reduces storage needs but can increase CPU usage during complex joins across many different tables. | High storage demand to keep multiple backup copies. System performance may drop during the backup process. | Requires additional storage space for the indexes. Needs ongoing maintenance to keep those indexes optimized. | Increases processing overhead due to data encryption tasks and the enforcement of strict access controls. | Monitoring tools add a small amount of overhead to the database server during data collection. | Optimizes storage through tiering. Requires ongoing maintenance for policy enforcement and moving data between tiers. |
| Expected Outcomes 📊 | Less data redundancy and better integrity. Complex queries may run slower if you do not use indexing. | Reliable data recovery and minimal downtime. Helps ensure the organization follows strict compliance and safety standards. | Dramatically faster query performance and much more efficient retrieval of data from large datasets. | Keeps sensitive data safe, ensures strict regulatory compliance, and provides clear audit trails for security teams. | Early resolution of bottlenecks, faster query speeds, and better utilization of existing hardware resources. | Significant storage cost savings and improved performance by offloading old data to cheaper storage tiers. |
| Ideal Use Cases 💡 | Systems that require high data integrity, such as banking platforms, healthcare records, and ERP software. | Any system where data loss is unacceptable, including financial transaction logs and patient medical records. | Read-heavy systems that need fast access, such as e-commerce sites, content platforms, and analytical dashboards. | Enterprises handling sensitive or regulated data, such as personal information, financial records, and intellectual property. | Environments that demand high performance, such as SaaS applications and platforms for real-time data analytics. | Organizations managing large data volumes with diverse retention needs, such as big data archives and logs. |
| Key Advantages ⭐ | Removes data anomalies, maintains record consistency, and makes the process of updating data much simpler. | Prevents data loss and ensures business continuity. Provides peace of mind during unexpected system failures. | Significantly improves query response times, which leads to a much better experience for the end user. | Protects private data, builds user trust, and ensures the organization meets all regulatory requirements. | Improves performance and resource use while helping to extend the lifespan of server hardware. | Lowers storage costs, improves data governance, and keeps the main database running at high speeds. |
| Tips 💡 | Start with 3NF. Evaluate the trade-offs of denormalization for speed. Document all database design decisions. | Use the 3-2-1 backup rule. Test recovery scripts often. Automate all monitoring and verification tasks. | Index the columns used most in queries. Review execution plans. Remove any redundant or unused indexes. | Apply the principle of least privilege. Use database firewalls. Keep all software patched and perform audits. | Set up automated alerts. Review slow query logs every week. Use database-specific performance optimization tools. | Define clear retention policies. Automate data movement workflows. Audit your data management practices on a schedule. |
Transforming Database Management from a Task to a Strategy
Managing data in a modern technical environment requires more than keeping servers online. It demands a strategic, disciplined approach where the database functions as a primary business enabler. Reviewing these ten database management best practices shows that high-quality administration is not a set of isolated chores. Instead, it is a system of integrated principles that strengthen your data infrastructure. There is a significant difference between a fragile system that requires constant firefighting and a high-performance engine that supports business growth and technical improvement.
IT professionals who apply these concepts move beyond basic administration to become architects of their organization's most important digital assets. You are no longer just fixing errors as they appear. You are engineering an environment that is secure, efficient, and ready for future scale. This change from maintenance to strategy defines expertise in the modern field. It ensures that data remains available and useful even as hardware or software requirements change.
From Checklist to Culture: The Core Takeaways for IT Professionals
The practices in this guide, from normalization to scalability planning, connect with each other. A backup strategy (Practice #2) loses its value if poor query optimization (Practice #5) makes the system unusable. Similarly, access controls (Practice #4) work better when supported by documentation (Practice #8) that defines user permissions clearly. If the documentation is missing, security audits become difficult and time-consuming.
View these principles as a continuous discipline rather than a one-time setup. Your approach must change as your technology stack, data volume, and organizational goals grow. Effective IT leaders stay flexible and update their methods as new tools and threats emerge.
Key strategic pillars to remember in your daily work:
- Proactive vs. Reactive: Develop a proactive mindset. Do not wait for a security breach, a server crash, or a performance lag to act. Set up security, monitoring, and recovery plans before they are needed. High-performing teams spend more time preventing problems than they do solving them.
- Performance is a Feature: Slow queries and bottlenecks hurt the user experience and business results. Indexing and optimization are essential requirements for a healthy database, not optional extras. Treat speed and efficiency as core goals during every stage of the development process.
- Data Has a Lifespan: Use Data Lifecycle Management to keep your database lean. This prevents the performance lag and high costs caused by keeping old, irrelevant data. Establish clear rules for when data should be archived to cheaper storage or deleted entirely to maintain system health.
- Consistency is Key: Use change management, version control, and clear documentation. These practices create a stable environment that reduces human error and helps teams work together. When every change is tracked and recorded, troubleshooting becomes faster and more predictable for everyone involved.
Your Actionable Path Forward to Mastery
Mastering these concepts takes time. To turn this knowledge into results, take an incremental approach. Do not try to change everything at once. Find the most urgent area in your environment and start there. Small, consistent improvements often lead to the best long-term results for the stability of your systems.
Immediate steps to improve your expertise:
- Conduct a Health Audit: Compare your current database setup against the ten practices. Find the gaps. Is your recovery plan tested? Is your documentation current? Use this audit to build a plan for improvement. Look for "dark data" that occupies space without providing value and identify users with unnecessary permissions.
- Focus on High-Impact Areas: Choose one or two practices to fix first. Many teams start with Performance Monitoring and Query Optimization (Practice #5). This often shows fast results for users and builds support for more changes. Even small adjustments to a frequently used query can reduce CPU usage across the entire cluster.
- Create a Documentation Standard: Start today. Every schema update or stored procedure must be thoroughly documented (Practice #8). This habit helps with long-term maintenance and team knowledge. When a new person joins the team, they should be able to understand the data structure by reading your records rather than guessing.
- Commit to Learning: Data management changes fast. New technologies and security threats appear often. Spend time on education to keep your skills current. Stay updated on the latest encryption standards and storage technologies to ensure your databases remain reliable. Adopting these best practices is the base of a successful career in the modern IT field.
Ready to turn theory into certified expertise? MindMesh Academy provides hands-on training and certification preparation for platforms like AWS and Azure. These principles apply to those platforms every day. Improve your skills and validate your proficiency by exploring our expert-led courses at MindMesh Academy: MindMesh Academy.
Ready to Get Certified?
Use expert-curated study guides, practice exams, and flashcards at MindMesh Academy. Spaced repetition helps you pass with confidence:

Written by
Alvin Varughese
Founder, MindMesh Academy
Alvin Varughese is the founder of MindMesh Academy and holds 18 professional certifications including AWS Solutions Architect Professional, Azure DevOps Engineer Expert, and ITIL 4. He's held senior engineering and architecture roles at Humana (Fortune 50) and GE Appliances. He built MindMesh Academy to share the study methods and first-principles approach that helped him pass each exam.