Top 10 Configuration Management Best Practices for 2026
Effective configuration management defines the boundary between stable, secure systems and chaotic, vulnerable ones. Ad-hoc changes, undocumented dependencies, and inconsistent environments often result in outages, security breaches, and compliance failures. For professionals pursuing certifications such as ITIL, AWS, Azure, or PMP, mastering a structured configuration strategy is a necessary skill and a significant career advantage.
This article provides a prioritized and actionable list of 10 essential configuration management best practices for IT teams and certification candidates. Every practice includes its core rationale, specific implementation steps, common pitfalls, and exam-relevant notes. These details help you pass with confidence and apply these principles to your daily work. MindMesh Academy aims to connect theoretical concepts with actual technical application.
Our goal is to offer a detailed guide to infrastructure control. You will learn to establish a single source of truth, automate deployments, manage change, and stop configuration drift. These insights provide tools for building resilient systems, helpful for those studying for the ITIL 4 Foundation exam, preparing for the AWS Certified DevOps Engineer Professional, or aiming to bring order to a chaotic environment. Following these proven strategies allows teams to minimize operational risk and increase efficiency. When managed correctly, your infrastructure remains a reliable asset that supports business goals instead of creating constant technical debt. Proper documentation and automated tracking ensure that every component is accounted for during internal audits or disaster recovery efforts. These practices prepare you for current exam requirements and for the high-pressure demands of modern technical work in any industry.
1. Maintain a Single Source of Truth (SSOT)
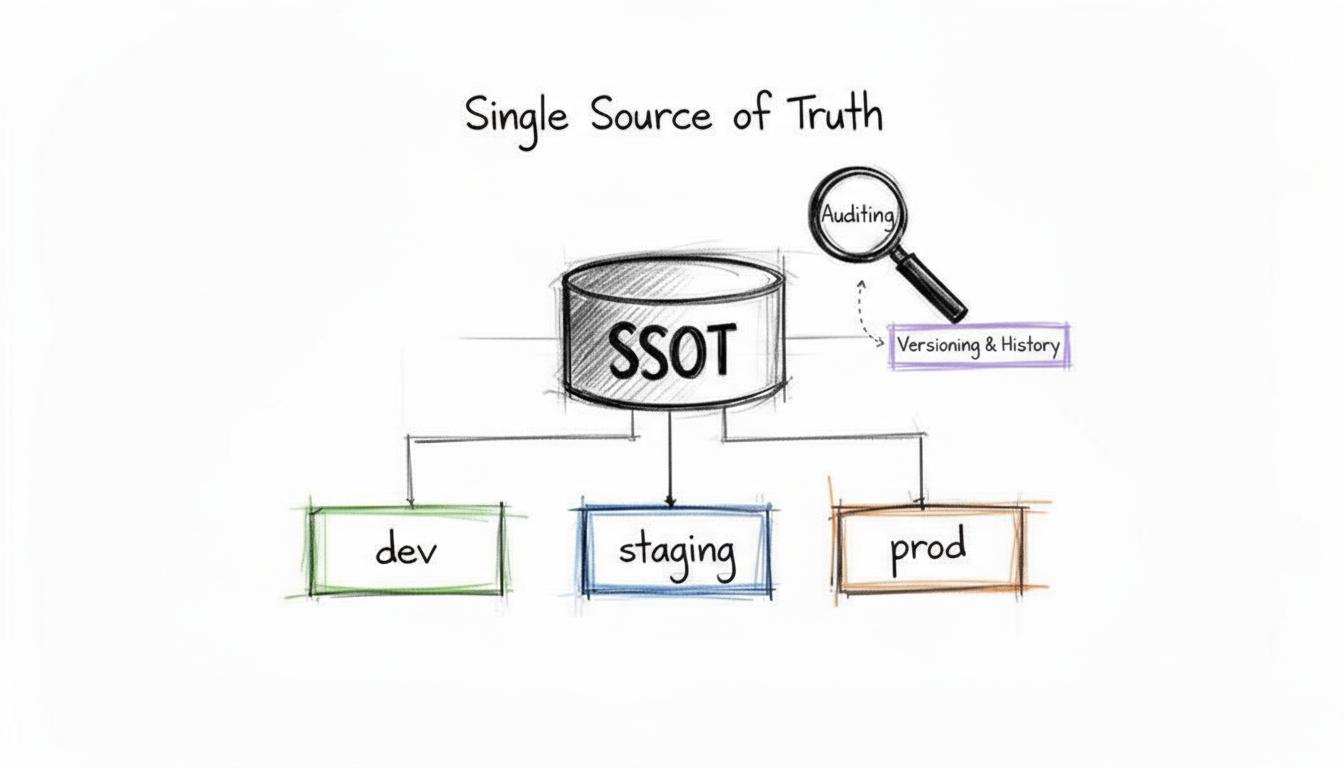
Establishing a Single Source of Truth (SSOT) serves as the base for any configuration management strategy. This practice involves building a centralized, authoritative repository to house all Configuration Items (CIs), their specific attributes, and their connections to one another. By centralizing this data, every team member—from developers to security auditors—references the same current information. This removes the risks associated with configuration drift and prevents data from being locked away in silos or "tribal knowledge" known only to a few employees.
An SSOT functions as the definitive record for your entire IT environment. In an AWS setup, for example, your Infrastructure as Code (IaC) templates stored in Git may act as the SSOT for infrastructure provisioning. Meanwhile, a Configuration Management Database (CMDB) like ServiceNow functions as the SSOT for service relationships and business criticality, which is a key part of ITIL processes. When an engineer needs to make a change, they update the SSOT first. Automated systems then push that change to the required environments. This maintains consistency across development, staging, and production. Systems become more predictable and easier to audit.
Why It's a Top Practice
If you lack an SSOT, configuration data ends up scattered across local files, random spreadsheets, and chat logs. Fragmentation leads to conflicting information, manual errors, and long delays when troubleshooting. It is difficult for an IT team to fix a service outage if different engineers have different records for a server's IP address or an application's version. Centralizing this data provides a reliable base for automation and compliance standards like SOX or HIPAA. It also supports the "Information and Technology" activity in the ITIL 4 value chain by ensuring decision-makers have accurate data.
Actionable Implementation Steps
- Select the Right Tool: Pick a repository that matches your data type and existing setup.
- For Infrastructure: Use a Git repository (such as GitHub, GitLab, or Azure DevOps) to store IaC files for tools like Terraform, Ansible, or CloudFormation.
- For Service and Asset Relationships: Use a dedicated CMDB like BMC Helix, ServiceNow, or Ivanti ITAM to track CIs and how they depend on one another.
- For Sensitive Data: Store API keys, passwords, and certificates in a secrets management tool such as HashiCorp Vault, AWS Secrets Manager, or Azure Key Vault.
- Define Your CIs and Relationships: Identify your most critical CIs first, such as servers, databases, cloud services, and network devices. You must map how these items relate to one another to understand the impact of any single change.
- Enforce Access Control and Auditability: Set up strict Role-Based Access Control (RBAC) to limit who can modify configuration data. Every change must be recorded so you know who changed what and when it happened. Visibility here is required for many security standards, including those in CompTIA Security+ SY0-701 (verify current exam codes on the vendor site).
- Automate and Integrate: Link your SSOT directly to CI/CD pipelines and tools like Ansible. When the source code or configuration file changes, the automation should apply it to the environment. This minimizes manual mistakes and ensures the live state matches the documented state.
Common Pitfalls and How to Avoid Them
One frequent error is treating the SSOT as a static, write-only database that nobody updates. Engineers often make manual fixes directly in production without updating the central record. This causes the SSOT to become obsolete quickly. To prevent this, use automated audits to compare the SSOT against the actual state of your environment. Tools like AWS Config or Azure Policy can identify drift. You can set these tools to either fix the problem automatically or alert the team for manual review. Maintaining this loop ensures that the SSOT remains a trustworthy guide for the organization.
Reflection Prompt: Look at your current environment. What is the most impactful first step you could take to build a better SSOT? Which specific CI should your team prioritize documenting first?
2. Implement Version Control for All Configurations
Applying version control to configurations is a standard requirement for modern operations. This involves using a Version Control System (VCS) like Git to track changes to configuration files, including application settings, server images such as AMIs in AWS, Dockerfiles, infrastructure-as-code scripts, and network policies. By treating configuration as code, every modification becomes a commit with a designated author, timestamp, and explanation of the change.
This practice provides an auditable history of the desired state of a system. If a change introduces an error—a frequent occurrence in DevOps roles—teams can identify the specific commit and revert to the last known good configuration. This capability reduces the Mean Time to Recovery (MTTR) significantly. It moves configuration management from an opaque, manual task into a transparent, collaborative, and auditable engineering discipline, much like application code development. This knowledge is essential for anyone preparing for the AWS Certified DevOps Engineer Professional exam.
Why It's a Top Practice
Without version control, configuration changes are hard to track, audit, or reverse. This unregulated approach leads to configuration drift, where environments become inconsistent and unreliable. Debugging a production outage is difficult if you cannot see who changed a firewall rule or when a specific environment variable was updated. Version control creates accountability. It enables peer reviews, automated testing, and a reliable history for debugging. These records are necessary for security audits, SOC 2 compliance, and meeting various regulatory requirements.
Actionable Implementation Steps
- Centralize Configurations in Git: Store all configuration files, including Kubernetes manifests, Terraform code, Ansible playbooks, server build scripts, and cloud network definitions, in a central Git repository like GitHub, GitLab, or Azure Repos. Centralization ensures that the repository serves as the single source of truth for the entire infrastructure, making it easier to manage permissions and visibility across the organization.
- Write Meaningful Commit Messages: Require descriptive commit messages that explain the reasoning behind a change. For example, "feat: Add new S3 bucket for audit logs to satisfy compliance requirement" is more useful than "update config." This context helps teams understand the intent behind changes months after they were committed and allows for better tracking when linked to internal ticketing systems.
- Implement a Branching Strategy: Define a clear strategy such as GitFlow, GitHub Flow, or Trunk-Based Development. Use feature branches for new changes and merge them into the main branch via pull requests after a code review. To improve your version control strategy, consider advanced methodologies like Trunk-Based Development to improve team collaboration and deployment speed.
- Protect Key Branches: Use branch protection rules to prevent direct pushes to the
mainorproductionbranches. Require pull request reviews from at least one other team member and passing status checks, such as automated unit tests or syntax validation, before a merge. This adds a layer of quality assurance that prevents accidental deletions or unvetted configuration changes from reaching production environments.
Common Pitfalls and How to Avoid Them
A dangerous mistake, often highlighted in certifications like CompTIA Security+, is storing sensitive data like passwords, API keys, or TLS certificates directly in Git. Because Git history is persistent, deleting a secret in a later commit does not remove it from the repository's history. To prevent this, use a dedicated secrets management tool like HashiCorp Vault, AWS Secrets Manager, or Azure Key Vault. Reference these secrets from your configuration files using variables. Use .gitignore files and pre-commit hooks to scan for and block secrets from being committed. The code in Git should only point to these external values, keeping the sensitive data secure while maintaining the benefits of version control.
3. Establish Clear Configuration Item (CI) Classification
Developing a logical classification system for your Configuration Items (CIs) is a fundamental step in building a functional CMDB. You must categorize every asset in the IT environment—including physical servers, virtual applications, databases, network hardware, and technical documentation—using specific criteria like asset type, criticality, and overall business impact. A structured classification scheme turns your CMDB into a tool for active decision-making. This aligns with ITIL Service Configuration Management principles.
When you organize CIs logically, you create a path for prioritized management and faster incident resolution. Consider an AWS RDS database server labeled as a "Tier 1" CI. If this server supports a customer-facing e-commerce application, its status ensures that any incident or change request involving it receives immediate attention from the operations team. This system provides necessary context for managing complex environments where cloud resources change constantly. Without identifiers, teams struggle to see how failures ripple through the service chain.
Why It's a Top Practice
Treating all CIs with the same level of urgency creates waste. If you do not classify items, a non-essential internal development tool might consume the same level of scrutiny and resources as a critical production server. This lack of clear priority slows down incident response and increases the risk of downtime for essential services. Classification allows your staff to see the business context of an asset instantly. They can then apply the correct level of governance and accurately predict how a change might affect the rest of the network. ITIL practitioners use these classifications to ensure that resources go where they are needed most during high-pressure outages.
Actionable Implementation Steps
- Define Classification Tiers: Establish a hierarchy based on how much an asset affects the business. You might use Tier 1 for mission-critical services, Tier 2 for business-critical operations, Tier 3 for supporting roles, and Tier 4 for non-essential tools. Ensure these tiers match your existing service-level agreements (SLAs), Recovery Time Objectives (RTOs), and Recovery Point Objectives (RPOs).
- Establish CI Types: Group CIs by what they do. Standard categories include Hardware (Physical Servers, Switches), Software (OS, Middleware, Databases), Cloud Resources (EC2 Instances, S3 Buckets, Azure VMs, AKS Clusters), and Documentation (Manuals, DR plans). You can use the ITIL framework or the ServiceNow CMDB structure as a baseline for these categories.
- Implement Consistent Naming Conventions: Standardize all item names. A reliable format includes the environment, asset type, function, and geographic location. Examples include
prod-web-ecom-01for a production web server oraws-eu-west-1-prod-web-app-01for a cloud-native application component. - Automate Tagging and Labeling: Use the native tagging tools provided by your cloud provider. Apply AWS resource tags for
OwnerorCriticality, or use Kubernetes labels likeappandenvto identify containers. Connect these tags to your Infrastructure as Code (IaC) templates so that every new resource is classified the moment it is provisioned.
Common Pitfalls and How to Avoid Them
Many organizations build classification systems that are too rigid or complex to maintain over time. If the rules are too difficult to follow, teams will ignore them or apply them inconsistently. To prevent this, start with a basic scheme and add detail only when necessary. Document the logic behind each classification so new staff understand the requirements. Review these categories with business leaders annually to confirm they still match company goals. You can use policy-as-code tools like Open Policy Agent, AWS Config Rules, or Azure Policy to audit your environment automatically. These tools flag or fix CIs that lack the correct tags, helping you maintain compliance without manual effort.
Reflection Prompt: How does your organization currently classify its IT assets? Are there any inconsistencies that could lead to misprioritized work or overlooked risks?
4. Automate Configuration Deployment and Validation
Manual configuration changes frequently lead to errors, system inconsistencies, and unexpected downtime. Automating configuration deployment and validation is a fundamental practice that uses software tools to apply and check settings programmatically. This method ensures every environment is set up and updated using the same logic. By removing manual intervention from the process, teams can speed up deployment cycles and build infrastructure that is more resilient and predictable. Mastering these automated workflows is a necessary skill for IT professionals working in modern operations.
By turning your configurations into code (IaC) and placing them into an automated pipeline (CI/CD), you build a process that is both repeatable and easy to audit. Tools like Terraform, Ansible, Chef, Puppet, or AWS CloudFormation read configuration files from your Single Source of Truth and apply them to your target systems. Automation continues after the initial push; automated validation checks confirm that the live system matches the state defined in your code. This provides immediate feedback and stops configuration drift before it causes an outage. You can find more about these patterns in these CI/CD pipeline best practices.

Why It's a Top Practice
Automation is the engine for modern configuration management. It solves the common problem where code works on a developer's laptop but fails in production by ensuring that every environment—development, staging, or production—uses identical templates. This consistency is vital for performing reliable tests, troubleshooting issues quickly, and maintaining a secure posture. It is a necessary component of any mature DevOps or ITIL framework. Automation removes the risk of human error during repetitive tasks and decreases the time it takes to get new features to users. This allows engineers to focus on architectural strategy rather than fixing broken manual configurations.
Actionable Implementation Steps
- Choose Your Automation Tools Wisely: Select tools based on your specific infrastructure. Use Terraform for multi-cloud environments, AWS CloudFormation for AWS-native setups, Azure Resource Manager (ARM) for Azure, or Google Cloud Deployment Manager for GCP.
- Use Configuration Management Software: Manage settings at the operating system level with Ansible, Chef, Puppet, or SaltStack. If you work in the Amazon cloud, learn more about services like AWS Systems Manager and AppConfig to see how managed services simplify these tasks.
- Write Idempotent Scripts and Configurations: Ensure your automation code is idempotent. This means running a script once or a hundred times results in the same final state. This logic prevents the script from making duplicate changes—like adding the same line to a config file twice—which helps maintain stability.
- Integrate into CI/CD Pipelines: Put your deployment scripts inside a CI/CD pipeline using platforms like Jenkins, GitLab CI, GitHub Actions, Azure Pipelines, or AWS CodePipeline. Set these to trigger automatically when an engineer commits new code or after a build passes its initial tests.
- Implement Automated Testing and Validation: Include a validation step in your deployment pipeline. Use testing tools like Terratest for Terraform or InSpec for Chef to confirm the configuration was applied correctly. These tests verify that the system is healthy and services are responding before any traffic reaches the update.
Common Pitfalls and How to Avoid Them
A common mistake is relying on "fire-and-forget" automation that lacks validation or rollback mechanisms. For example, an Ansible playbook might finish its run without errors even if the service it was supposed to configure fails to start. To prevent these failures, always include post-deployment checks that verify the health of the system. You should also develop automated rollback procedures to revert to the last known good state if a validation test fails. This creates a safety net that gives teams the confidence to deploy changes more often. This focus on reliability is a major theme for certifications like the AWS Certified SysOps Administrator.
Reflection Prompt: What manual configuration tasks in your current role are most prone to error or take up significant time? How could automation tools like Ansible or Terraform address these challenges?
5. Implement Comprehensive Change Control Processes
Establishing a formal change control process provides the structure needed to manage IT environments with accountability. This practice involves creating documented procedures to request, evaluate, approve, and review all configuration changes. The primary objective is to ensure that every modification is deliberate, analyzed for potential impact, and fully traceable. It aligns with ITIL Change Enablement (formerly Change Management) and is a core component of project management disciplines such as the PMP certification.
A structured workflow reduces risks like unplanned outages, security gaps, and compliance failures often triggered by unauthorized or poorly planned modifications. By formalizing the lifecycle of a change—moving from the initial proposal to a final post-implementation review—organizations maintain operational stability without stopping technical progress. This framework acts as a technical filter, ensuring that only beneficial and verified changes reach the production environment.
Why It's a Top Practice
Configuration management becomes unmanageable without formal oversight. When engineers make ad-hoc changes without documentation or review, the result is configuration drift. This makes it difficult to troubleshoot outages or restore systems to a known good state. A disciplined process provides the governance required to prevent these failures. It ensures that stakeholders from security, operations, and business units remain informed of upcoming shifts. This oversight is vital for organizations in regulated sectors where audit trails are mandatory for maintaining service stability.
Actionable Implementation Steps
- Define Change Types: Classify every change based on its risk level and potential impact on the business.
- Standard Changes: These are pre-approved, high-frequency, and low-risk actions. Examples include patching non-critical servers or updating a single user’s permissions. These follow an automated path with minimal human intervention.
- Normal Changes: These are non-emergency modifications that require a technical assessment, scheduling, and formal approval. Major application upgrades or large-scale network reconfigurations fall into this category.
- Emergency Changes: These address critical incidents that threaten service availability. While they might bypass certain approval stages initially to restore service quickly, they must undergo a post-implementation review and full documentation once the crisis passes. Patching a zero-day vulnerability is a common example.
- Establish a Change Advisory Board (CAB): Form a cross-functional group responsible for reviewing and approving complex or high-impact changes. The CAB should include members from development, security, and operations. Their role is to prioritize requests and assess how a change in one area might disrupt another.
- Automate the Workflow: Deploy an ITSM tool such as ServiceNow, Jira Service Management, or BMC Helix ITSM. These platforms log requests, route them to the correct approvers, and track progress. More importantly, they link change requests directly to Configuration Items (CIs) in your database.
- Integrate with Automation and Version Control: Connect your change control system to your CI/CD pipeline. For instance, you can configure a deployment to trigger only after a change request receives a final digital signature. This ensures that only authorized code reaches the server. For more detail, explore how to apply change management principles within AWS CloudFormation.
Common Pitfalls and How to Avoid Them
The most common failure occurs when the process becomes too bureaucratic and slow. If approvals take weeks, agile development teams will often find workarounds, creating "shadow IT" and bypassing the system entirely. This behavior defeats the purpose of the practice. To prevent this, keep the process lean and efficient. Use automation to handle standard changes and only involve the CAB for high-risk items. The goal is to provide visibility and control without becoming a bottleneck that prevents the organization from moving fast. Regularly audit your metrics to see where delays happen and adjust the workflow to better support business needs.
6. Document Configuration Relationships and Dependencies
Mapping the connections and dependencies between Configuration Items (CIs) is a vital part of managing technical environments. This process involves building a reliable map showing how servers, applications, databases, network hardware, cloud services, and external APIs interact. Having this visibility allows for more accurate impact analysis, faster resolution of technical incidents, and smarter change management. Without this level of detail, IT operations teams usually find themselves guessing when systems fail.
If you don't understand these dependencies, a minor update to a single component might trigger a total failure in a separate system. For instance, you might update a shared software library that a critical, legacy application requires to function. By mapping these connections, teams can forecast the ripple effects of a planned change, find the source of an outage quickly, and verify that the system architecture remains stable and ready for support.
Why It's a Top Practice
In modern, distributed cloud systems, every component is connected to something else. Failing to record these dependencies creates blind spots that hinder troubleshooting and risk assessment. Visualizing these relationships converts unknown risks into predictable factors. This allows teams to make data-driven decisions that protect both service availability and overall performance. This approach aligns with ITIL Service Operation and Site Reliability Engineering (SRE) principles, directly improving Mean Time to Detect (MTTD) and Mean Time to Resolve (MTTR) for critical incidents.
Actionable Implementation Steps
- Use Discovery and Mapping Tools: Deploy automated tools to scan your environments and build initial dependency maps.
- For Application Topology: Tools like Dynatrace, AppDynamics, New Relic, or DataDog can visualize how application components communicate.
- For Infrastructure and Cloud Resources: ServiceNow Discovery, Splunk IT Service Intelligence, or AWS Systems Manager Explorer help identify infrastructure components and their specific links.
- Record Business Context and Service Maps: Look beyond the technical connection. Document which business services rely on specific applications and infrastructure. Build end-to-end service maps that show how CIs deliver value. For example, specify that the "e-commerce checkout" service requires the "payment gateway API," "customer database," and "inventory microservice."
- Connect with Change Management: Require a dependency review for every change approval process. Every change request should name the CIs that will be affected directly or indirectly. This allows the Change Advisory Board (CAB) to evaluate the total blast radius before approving a proposal.
- Update Runbooks and Playbooks: Add dependency data to your operational runbooks and incident response playbooks to assist engineers. A clear map helps teams identify upstream or downstream causes during a crisis, which speeds up the recovery process.
Common Pitfalls and How to Avoid Them
The most frequent mistake is building a dependency map once and failing to maintain it. This results in an outdated and misleading view of the environment. Manual mapping is no longer possible in fast-moving cloud environments. To prevent this, set up regular, automated audits that compare your documentation against the live state of your systems. Set up processes where architectural changes, often managed through Infrastructure as Code (IaC), trigger an update to the dependency data automatically. This ensures the records stay current as the environment changes. Use tools that can detect and update these relationships in real time.
Reflection Prompt: Recall a recent incident or change that had unexpected ripple effects. Could better dependency documentation have prevented or mitigated the issue?
7. Maintain Accurate and Current Inventory Records
Keeping inventory records accurate and current provides the foundation for configuration management. This practice requires the constant discovery, tracking, and verification of every Configuration Item (CI) across your IT infrastructure. An updated inventory acts as the primary dataset for all other configuration tasks, including change management, security vulnerability scans, incident response, and budget planning.
Operating without a reliable inventory means flying blind. You cannot manage or protect what you do not know exists. This practice ensures your Configuration Management Database (CMDB) or asset registry matches the actual state of your infrastructure. This includes hardware, software, cloud resources like AWS EC2 instances or Azure Functions, and the relationships between them. Accuracy here allows for better decision-making, tighter security, and strict adherence to data residency or licensing requirements.
Why It's a Top Practice
Outdated inventory records result in security gaps, failed audits, and wasted budget. Unmonitored assets, often called shadow IT, create risks by introducing unpatched systems or entry points for attackers. Forgotten cloud resources or ghost servers continue to generate monthly bills for services no one uses. By maintaining a precise, real-time inventory, organizations can close these security holes—a primary objective for CompTIA Security+ candidates. Precise records also improve resource allocation and software license management. When auditors arrive, you can provide a clear, verifiable list of every IT asset. This level of visibility is a fundamental requirement for high-level configuration management.
Actionable Implementation Steps
- Implement Automated Discovery Tools: Use software that scans networks, virtual environments, and cloud platforms to identify assets without manual intervention.
- On-premises: Use network scanners and endpoint management tools such as Microsoft SCCM.
- Cloud: AWS Config, Azure Inventory, and Google Cloud Asset Inventory provide constant discovery and can sync directly with your CMDB.
- CMDB-integrated: Software like ServiceNow Discovery scans the environment to populate a CMDB with granular CI details.
- Establish a Reconciliation Cadence: Set up automated schedules to compare discovered data against existing CMDB records. This identifies discrepancies, such as active CIs that are missing from the registry or retired CIs that still appear in the database.
- Assign Asset Ownership and Lifecycle Management: Every CI needs a specific owner who is accountable for its lifecycle. This person manages the asset from initial procurement and provisioning through to final decommissioning. This clarifies who is responsible for maintenance, security updates, and cost control. Ensure these steps align with your IT Asset Management (ITAM) workflows.
- Integrate with Other Systems: Link your inventory data with ITSM, financial, security, and monitoring platforms. This provides a single view where technical details connect to business context. For example, you can link a specific server to a cost center or a critical customer-facing service.
Common Pitfalls and How to Avoid Them
Relying on manual processes for inventory updates is a mistake that slows down operations. Manual entry leads to human error and cannot scale to meet the speed of modern cloud environments or large data centers. To prevent this, focus on automation from the start. Use discovery agents and API integrations to keep data collection moving. While manual checks are still useful for physical hardware audits, they should only support your automated systems. A strong strategy relies on automated discovery and reconciliation to keep the inventory as a trusted source of truth for all configuration-related decisions.
Reflection Prompt: How confident are you that your organization's current IT inventory is 100% accurate? What hidden risks or costs might inaccurate records be introducing?
8. Use Infrastructure as Code (IaC) for Consistency
Infrastructure as Code (IaC) changes how organizations manage and provision their technology by treating infrastructure setup as a software development task. Instead of using a web console or manual scripts to configure hardware, engineers define servers, networks, databases, and load balancers in human-readable, versioned text files. This code-based approach allows for automated testing, version control, and repeatable deployments. It serves as a fundamental part of configuration management and is a key topic for cloud certifications like the AWS Certified Solutions Architect or the Azure Administrator.
When you define an entire infrastructure in code, you create a permanent blueprint. This document can be versioned, shared across teams, and executed to build identical environments on demand. This method removes the configuration errors that happen with manual entry. It ensures that the environment used for staging is exactly the same as the one used in production, leading to higher consistency. IaC also supports immutable infrastructure. In this model, you do not modify running systems to apply changes. Instead, you use code to deploy new infrastructure and decommission the old systems.

Why It's a Top Practice
Managing infrastructure by hand is slow and does not scale. Consider the work required to set up 100 new web servers, each needing specific networking, security groups, and monitoring agents. IaC fixes this by turning these definitions into code that is easy to audit and repeat at scale. It acts as the engine for DevOps and Site Reliability Engineering (SRE) by helping teams build, test, and release software and infrastructure with greater speed and predictability.
Using code to manage systems also reduces configuration drift. This happens when servers slowly change over time until they no longer match their original setup. Because the code is the source of truth, you can find and fix these differences quickly. It also strengthens disaster recovery. If a data center fails, you can use your code repository to rebuild your entire environment in a different region in a fraction of the time it would take to do it manually.
Actionable Implementation Steps
- Choose the Right IaC Tool: Select a tool that fits your current cloud providers and technical requirements.
- Multi-Cloud: Terraform is a popular choice for provisioning resources across AWS, Azure, Google Cloud, and on-premises environments.
- AWS-Specific: AWS CloudFormation provides native provisioning for resources within the AWS environment.
- Azure-Specific: Azure Resource Manager (ARM) templates or Bicep offer native support for Azure resources.
- Configuration Management: After the hardware is ready, use tools like Ansible, Chef, or Puppet to manage operating system settings and application software.
- Version Control Everything: Store every
.tf,.yml,.json, and.bicepfile in a Git repository. This keeps a full history of every change made to your systems. It makes collaboration easier through pull requests and allows you to roll back to a stable state if a new deployment fails. - Start with a Small, Defined Scope: Do not try to move your whole company to IaC at once. Start with one non-critical service. This gives your team space to learn the tools and fix their internal processes before moving to critical systems. For example, you might start by codifying an S3 bucket or a single development EC2 instance.
- Embrace Modularity and Reusability: Break your code into small, reusable modules rather than one long file. This reduces duplication and makes the code easier to update. You could create a standard "web server module" that different teams use to ensure everyone follows the same security standards.
Common Pitfalls and How to Avoid Them
One common mistake is building monolithic configurations that are too large to understand or manage. Another is failing to manage the state of the infrastructure, which causes problems when multiple people try to make changes. To avoid these issues:
- Structure Your Code Logically: Keep your files organized by environment, such as dev, staging, and production. You should also separate core networking code from your database or application code.
- Use Workspaces and State Files: If you use Terraform, use workspaces or separate remote state files for each environment. This prevents a change meant for a test environment from affecting production.
- Implement Review Processes: Require a peer review for every code change before it is merged. This helps catch mistakes before they reach your live environment.
- Address Secrets Management: Never write passwords or API keys directly into your files. Use a dedicated secret management tool and have your IaC files call those secrets when needed.
Taking this layered, modular approach makes your systems easier to read and more secure. It also lowers the risk of deployment errors that can lead to expensive downtime.
Reflection Prompt: If you were to introduce IaC to your current infrastructure, which cloud provider or on-premises system would you target first, and what benefits do you anticipate?
9. Establish Baseline Configurations and Standards
Establishing baseline configurations is a core requirement for managing IT infrastructure. It involves defining and documenting an approved, standardized state for each type of Configuration Item (CI). These baselines act as a template, providing a known-good configuration for servers, network devices, databases, and applications. All deployments and changes are measured against this standard to ensure consistency and security across the organization. This practice is a central part of most security and compliance frameworks.
This approach is fundamental to creating stable environments. By defining what a correctly configured system looks like, you create a clear reference point for automation, auditing, and troubleshooting. Any deviation from the baseline, known as configuration drift, can be identified and corrected quickly. This prevents security vulnerabilities and operational issues from causing downtime. For certifications like CompTIA Security+, understanding how to implement baselines is a requirement for proving you can manage an organization's security posture.
Why It's a Top Practice
Without established baselines, configurations become inconsistent. Each new server or application might be set up differently, introducing unknown variables that make the environment unpredictable and difficult to manage. Baselines enforce uniformity, which is required for scaling operations and meeting security requirements (e.g., CIS Benchmarks, DISA STIGs, NIST). They provide a clear, auditable record of the desired state, simplifying compliance checks and proving that the IT team is following required protocols. Consistency helps ensure that systems behave as expected across all environments.
Actionable Implementation Steps
- Define Your Standards: Start by adopting industry-recognized security and configuration rules.
- Operating Systems/Applications: CIS Benchmarks (Center for Internet Security) provide specific guidance for hardening various systems and software.
- Government/Defense: DISA STIGs (Defense Information Systems Agency Security Technical Implementation Guides) offer strict security requirements for highly sensitive environments.
- Cloud Resources: The AWS Well-Architected Framework, Azure Security Benchmarks, or Google Cloud security documentation provide guidelines for secure cloud deployments.
- Document and Version Baselines as Code: Store your baseline configurations as code using Ansible playbooks, Terraform modules, Dockerfiles, or Golden AMIs/Images. Keep these in a version control system like Git. This keeps configurations transparent, auditable, and easy to update as your security standards evolve.
- Automate Enforcement: Use configuration management tools (e.g., Ansible, Puppet, Chef, AWS Systems Manager State Manager) to apply and enforce these baselines on all systems. In cloud environments, services such as AWS Config Rules or Azure Policy can continuously check for compliance and alert teams if a resource drifts from the approved state.
- Create an Exception Process: Establish a formal, documented process for handling necessary deviations from the baseline. Every exception should be reviewed and justified, such as when an application requires an older configuration to function. These exceptions must be approved by security teams and re-evaluated on a regular schedule.
Common Pitfalls and How to Avoid Them
A frequent problem is creating baselines that are too rigid to work in the real world. If a baseline does not account for the differences between development and production environments, it can slow down engineering teams. To avoid this, design your baselines using a modular approach. Use variables and templates in your automation tools to allow for controlled, environment-specific changes while keeping the core security configuration the same. Review and update your baselines regularly to reflect current technology and new business requirements.
Reflection Prompt: Are there specific security benchmarks or compliance standards that your organization struggles to consistently meet? How could baseline configurations simplify this process?
10. Monitor and Report Configuration Compliance and Drift
Even with a functional Single Source of Truth and reliable automation, configurations will change over time. This movement, called configuration drift, happens when the actual state of a system moves away from its intended design. Drift occurs because of manual emergency fixes, unmanaged software updates, human error, or background system processes. Monitoring for this drift and reporting on compliance against established baselines is a vital configuration management best practice. This habit is necessary to maintain security, ensure services remain reliable, and simplify audits for standards like ISO 27001 or SOC 2.
This practice requires automated systems that frequently scan your environments. These tools compare the current state of Configuration Items (CIs) against the approved state stored in your SSOT, such as Infrastructure as Code files in Git. When the scanner detects a difference, it should trigger an alert, log a report, or start an automated repair. Constant validation ensures that your infrastructure stays secure and predictable. This prevents minor technical debt from turning into a major outage.
Why It's a Top Practice
Configuration drift is a leading cause of unplanned downtime and security vulnerabilities. Without active monitoring, a server that was perfectly secure last Tuesday might have a new open port or a critical security patch missing today. By checking for drift continuously, you move configuration management from a static setup task to a dynamic cycle of enforcement. This proactive stance helps you identify and fix problems before they affect your users or lead to a breach. For IT operations and security professionals, this constant oversight is a reliable way to maintain a stable environment.
Actionable Implementation Steps
- Define Compliance Baselines (as discussed in Practice 9): You must establish version-controlled configuration baselines for every critical system. These baselines act as the "known good" state for your servers, network hardware, applications, and cloud accounts. Each baseline should be specific and measurable so that automated tools can test against them.
- Implement Continuous Monitoring Tools: Select tools that scan your infrastructure against your baselines at regular intervals.
- Cloud-Native: Use AWS Config with Config Rules, Azure Policy, or Google Cloud Security Command Center to watch cloud resources.
- General Purpose: Use Chef InSpec for compliance as code, or platforms like Tenable.io and Qualys. Many modern CMDBs also include modules for compliance tracking.
- Runtime: Use tools like Prometheus or Nagios to watch how services behave. Unusual behavior can often indicate that an underlying configuration has drifted.
- Automate Reporting and Alerting: Set up your monitoring platforms to build regular compliance reports for stakeholders. This includes IT managers, security officers, and external auditors. Dashboards offer a quick look at your current compliance status. You must set up immediate notifications for high-severity drift, such as a change to a firewall rule or the creation of an unauthorized admin account, to ensure these issues get fixed fast.
- Establish a Remediation Strategy: You need a plan for what happens when the system finds drift.
- Alert and Manual Review: This works best for low-risk changes or situations where a human needs to decide if the change was intentional.
- Automated Self-Healing: For critical or well-understood configurations, use tools like Ansible, Puppet, or Chef to fix the issue immediately. Cloud services like AWS Systems Manager State Manager or Azure Automation can also enforce the correct state. This Desired State Configuration model is a powerful defense against unauthorized changes.
Common Pitfalls and How to Avoid Them
The most common problem is alert fatigue. If your monitoring system sends notifications for every minor change, engineers will stop paying attention. This makes the monitoring useless. To prevent this, define your compliance thresholds carefully. Create a clear process for exemptions so that approved, temporary deviations do not trigger false alarms. Not every instance of drift is a disaster. Focus your high-priority alerts on changes that increase risk, like a security group opening a database to the public internet. Use weekly or monthly reports to track less critical issues. Regularly review your monitoring rules to remove noise and ensure the team only sees the most important data.
10-Point Configuration Management Best Practices Comparison
| Practice | Implementation complexity | Resource requirements | Expected outcomes | Ideal use cases | Key advantages |
|---|---|---|---|---|---|
| Maintain a Single Source of Truth (SSOT) | Medium–High (tooling and governance) | Centralized repositories, API integrations, RBAC, and audit logs | Consistent configurations, fewer manual errors, and clear ownership | Multi-team, multi-environment, and compliance-focused organizations | Eliminates conflicting info, improves decisions, and simplifies audits |
| Implement Version Control for All Configurations | Low–Medium (process and training) | VCS hosting, branching policies, and CI integration points | Full change history, rollback capability, and collaborative reviews | IaC, team collaboration, and change-tracked environments | Auditable changes, easy recovery, and support for code review |
| Establish Clear Configuration Item (CI) Classification | Medium (expertise required) | Taxonomy design, tagging schemas, and periodic review processes | Prioritized management and focused change control | Large inventories, risk-based operations, and SRE teams | Faster prioritization and better risk and resource focus |
| Automate Configuration Deployment and Validation | High (pipeline and tests) | IaC tools, CI/CD pipelines, test suites, and monitoring | Consistent deployments, faster delivery, and fewer errors | Frequent releases and scalable or cloud environments | Eliminates manual errors and ensures reproducible deployments |
| Implement Rigorous Change Control Processes | Medium (process heavy) | Workflow tools, approval hierarchies, and documentation | Traceable, evaluated changes and fewer unauthorized edits | Regulated environments and high-impact change scenarios | Accountability, compliance support, and reduced downtime |
| Document Configuration Relationships & Dependencies | Medium–High (mapping effort) | Discovery tools, visualization, and ongoing maintenance | Better impact analysis and faster root-cause identification | Complex service topologies and incident response teams | Prevents cascading failures and informs safe changes |
| Maintain Accurate and Current Inventory Records | Medium (continuous effort) | Discovery tools, reconciliation, and system integrations | Accurate asset visibility, license tracking, and cost control | Asset-heavy orgs, licensing management, and audits | Reduces shadow IT and improves capacity planning |
| Use Infrastructure as Code (IaC) for Consistency | Medium–High (skill and state management) | IaC tools, version control, and testing frameworks | Reproducible infra, reduced drift, and rollback capability | Cloud provisioning, repeatable environments, and DR | Infrastructure versioning, reduced drift, and faster recovery |
| Establish Baseline Configurations and Standards | Medium (policy and enforcement) | Standards docs, enforcement tooling, and review cadence | Consistent secure configurations and easier compliance | Security-conscious orgs, onboarding, and compliance | Improves security posture and simplifies troubleshooting |
| Monitor and Report Configuration Compliance and Drift | Medium (monitoring systems) | Continuous monitoring tools, dashboards, and remediation | Early drift detection and continuous compliance reporting | Security/governance teams and regulated environments | Proactive remediation and audit-ready evidence |
Turning Best Practices into Career Momentum
We have examined ten essential configuration management practices, ranging from establishing a single source of truth to the constant tracking of configuration drift. Each principle, including the rigor of version control and the utility of Infrastructure as Code (IaC), provides the structure required to manage modern IT environments. Applying these concepts effectively distinguishes a standard operation from a high-performing technical team. Successful implementation requires more than technical skill; it requires a commitment to consistency across every server, virtual machine, and container in your fleet. The transition from understanding these rules to active implementation is how you generate value for an organization.
Adopting these practices requires a fundamental change in how teams operate. You must move away from manual, reactive troubleshooting and toward automated, proactive management. Stop treating your infrastructure as a collection of individual, hand-tuned components. Instead, treat it as a unified system defined by code and governed by formal processes. This strategy reduces human error, speeds up deployment cycles, and ensures your systems stay in a known, compliant state. When your configuration is defined as code, every change is traceable, and every failure is easier to reverse. This shift prevents the "snowflake server" problem, where unique, undocumented changes make systems impossible to repair.
From Knowledge to Mastery: Your Action Plan
Developing expertise in configuration management is a continuous process rather than a single task. To turn the concepts in this article into practical results, use the following steps:
- Conduct a Gap Analysis: Focus on one critical system or application to begin. Measure your current workflow against the ten practices we discussed. Look for the most significant weaknesses. You might find that your network device configurations lack basic version control or that your Azure environments do not have automated compliance checks. Identify these specific failures first to prioritize your efforts.
- Select a Pilot Project: Do not try to overhaul your entire organization at once. Choose a low-risk project where you can show immediate impact. You might create a baseline configuration for a new group of AWS web servers using a Golden AMI. Alternatively, try moving the configuration files for a single application into a Git repository. This limited scope allows you to troubleshoot new processes safely.
- Prioritize Automation: Find the most repetitive and error-prone manual task in your current workflow. This often includes server provisioning, software updates, or security hardening. Use tools like Ansible or CloudFormation to automate these specific tasks. Starting here provides quick wins that help gain support from stakeholders for larger goals.
- Embrace Incremental Improvement: You will not achieve a perfect configuration state overnight. Focus on steady progress. Document what you learn during each phase and slowly expand your configuration management coverage. Continuous, documented improvement is more effective than a massive, complex rollout that teams eventually ignore. Celebrate when you successfully automate a single patch cycle or when a drift alert catches a manual change early.
The Career-Defining Impact of Configuration Management
Expertise in configuration management identifies you as a strategic IT professional. It shows you can think systemically, manage risk, and build resilient infrastructure. These skills are in high demand and form the basis of several prestigious certifications, including CompTIA Security+, AWS Certified SysOps Administrator, AWS Certified DevOps Engineer Professional, and ITIL 4 Foundation. When you demonstrate that you can manage configurations across a hybrid cloud environment, you show that you are ready for senior-level architectural roles.
In a technical interview or a certification exam, being able to explain how to manage configuration drift with AWS Config or how to design a change control process demonstrates senior-level capability. You prove that you can architect systems to prevent problems rather than just reacting to them. This proficiency often leads to higher-level responsibilities, such as leading a DevOps transition or managing large-scale cloud migrations. By applying these principles, you are managing your career path as much as you are managing your servers. You transition from being someone who follows a runbook to someone who writes the code that makes the runbook obsolete.
Ready to turn this knowledge into certified expertise? MindMesh Academy offers study paths and learning tools to help you master configuration management. Our platform identifies your knowledge gaps and prepares you to pass your certification exams with confidence. Start your personalized learning journey at MindMesh Academy.

Written by
Alvin Varughese
Founder, MindMesh Academy
Alvin Varughese is the founder of MindMesh Academy and holds 18 professional certifications including AWS Solutions Architect Professional, Azure DevOps Engineer Expert, and ITIL 4. He's held senior engineering and architecture roles at Humana (Fortune 50) and GE Appliances. He built MindMesh Academy to share the study methods and first-principles approach that helped him pass each exam.