A Guide to the Change Management IT Process
A formal change management IT process provides a structured framework. Planning slashes risk and minimizes disruption. From upgrading a server to rolling out new software across the company, this critical business function ensures IT changes meet specific goals and deliver on their promises without causing total operational chaos. These established processes maintain organizational stability during any deployment and subsequent transition.
Why Your Business Needs a Change Management IT Process
Replacing a car engine while driving down a highway is impossible without causing a catastrophe. Implementing major IT updates without a clear plan feels exactly like that scenario. It is chaotic, high-risk, and likely to fail. A structured change management process is more than bureaucratic red tape. It acts as a guardrail to keep operations stable when the technology supporting your business shifts.
Every update becomes a gamble without a formal process. Unmanaged changes often trigger a chain reaction of failures. This includes system outages that stop work and security breaches that expose sensitive data. In these environments, teams grow frustrated and waste time fixing preventable problems. The original goal of the change is often lost in the resulting confusion.
The High Cost of Unmanaged Change
IT transitions are difficult to manage. Statistics show that 70% of change initiatives fail (verify current industry data). These projects usually fall apart because of flawed execution rather than poor ideas. This high failure rate illustrates a gap where projects lack the necessary guidance to succeed. You can review more detailed change management statistics to see why a structured approach is so vital for success.
This failure rate leads to specific, costly problems for the business:
- Lost Productivity: When systems crash or employees struggle with unfamiliar software, the work stops. This creates a bottleneck that affects the entire company.
- Increased Security Risks: Rushed changes often leave gaps that attackers exploit to gain access to your network. Security must be part of the change, not an afterthought.
- Damaged Morale: Constant chaos causes employee burnout. This builds long-term resistance to future technology improvements or process updates.
A defined change management IT process turns reactive firefighting into a proactive strategy. It provides the visibility and accountability needed to ensure technology supports the business instead of disrupting it.
Managed vs Unmanaged IT Change Outcomes
A structured approach differs significantly from an "anything goes" method. Formal processes offer predictability and control, while unmanaged changes invite risk and instability. The table below compares these two approaches across four key areas of impact.
| Area of Impact | With Formal Change Management | Without Formal Change Management |
|---|---|---|
| Service Stability | Minimal downtime and predictable service levels are maintained. | Frequent, unexpected service outages and disruptions occur. |
| Risk Exposure | Risks are identified, assessed, and mitigated before implementation. | Security vulnerabilities and operational risks are often overlooked. |
| Resource Allocation | Resources are used efficiently for planned, approved activities. | Significant time is wasted on fixing avoidable errors. |
| Business Alignment | Changes are directly linked to business goals and priorities. | Changes are often disconnected from strategic objectives. |
One path results in control and reliability. The other leads to constant frustration and firefighting. The benefits of choosing a formal structure are clear for any organization that relies on stable technology.
Navigating the 5 Core Stages of IT Change Management
Successful IT changes require more than good intentions; they demand a repeatable framework. A transition follows a specific sequence of actions, moving from an initial concept to a fully functional solution. This is similar to the process of constructing a building. You do not simply arrive at a site and start laying bricks. You begin with a concept, develop a detailed blueprint, secure the necessary permits, execute the build with precision, and conduct a final inspection.
An effective change management IT process provides this same logical structure. It ensures every modification, whether it is a routine security patch or a significant infrastructure migration, is managed carefully. The primary objectives are to reduce operational risk and provide clear business value without disrupting daily activities.
Below are the five core stages that define this process.
Stage 1: Change Submission
Every modification begins with a specific need, an identified problem, or an idea for operational improvement. This initial phase, known as Change Submission or a Request for Change (RFC), is the point where the process becomes formal. It occurs when a stakeholder identifies an opportunity to enhance a system and documents the requirement.
For example, consider a sales department that relies on an outdated Customer Relationship Management (CRM) system. If the software frequently lags during peak hours or fails to sync data correctly, the sales manager would file a formal RFC. This document would outline the performance issues and propose migrating to a more capable platform. This is not a casual suggestion; it is a tracked request that triggers the formal workflow.
The following diagram illustrates how a request moves from the initial submission through analysis and toward the approval phase.
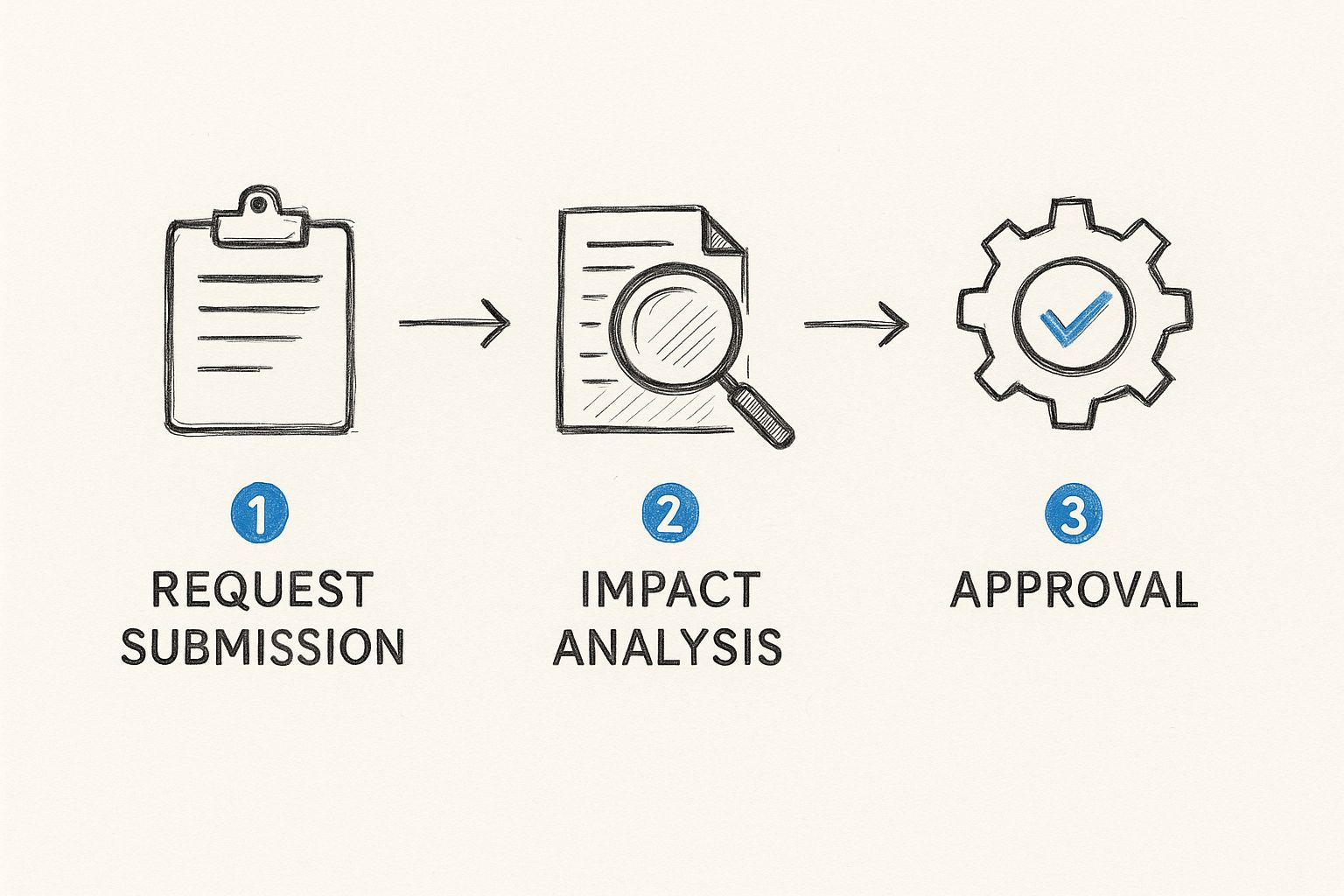
As shown, each phase serves as a mandatory gate for the next. This arrangement prevents teams from acting prematurely and ensures that every proposal is reviewed thoroughly before resources are committed.
Stage 2: Strategic Assessment
After an RFC is submitted, the team enters the Strategic Assessment phase. This functions as the blueprinting period. During this time, the technical team and stakeholders examine the proposal to determine its consequences for the broader environment. The focus is on understanding the potential impact, identifying risks, and calculating the resources required for a successful outcome.
Key activities during this stage usually include:
- Impact Analysis: This determines which systems, departments, and workflows will be affected. It also identifies which users will experience downtime or changes in their daily tasks.
- Risk Assessment: The team identifies potential failure points, such as security vulnerabilities, operational delays, or the possibility of exceeding the allocated budget.
- Resource Planning: This involves identifying the specific personnel, technical tools, and financial backing required to complete the work.
In the CRM migration example, the assessment team would identify every department that uses the current data. They would estimate the risk of data corruption during the transfer and establish a realistic timeline for the move, ensuring that the project does not interfere with critical end-of-quarter reporting.
Stage 3: Planning and Approval
With the assessment finished, the proposal moves to Planning and Approval. At this point, the team creates a granular implementation plan. This document is presented to the Change Advisory Board (CAB) or a similar governing body for final authorization.
The implementation plan serves as the primary technical guide for the change.
It must include a precise timeline, a communication plan to keep stakeholders informed, a rollback strategy to restore services if the change fails, and specific metrics to define success. This serves as the final check to ensure the logic is sound before any technical work begins.
Securing approval from the CAB is a vital step. The board reviews the assessment and the plan to confirm that the change aligns with organizational goals and that the risks are acceptable. In organizations using modern DevOps practices, these approvals are frequently automated for low-risk, frequent changes. You can see how this works with change management processes for IaC platforms that accelerate these approval cycles.
Stage 4: Building and Testing
Once the board provides authorization, the work moves into Building and Testing. The implementation team begins the actual technical labor, configuring hardware or writing code based on the approved specifications. For the CRM project, this would involve provisioning the new servers, configuring the software interface, and executing the data migration scripts.
Execution is only one part of the phase; testing is equally significant. The team moves the change into a controlled, non-production environment where they can look for bugs, latency issues, or integration errors. This step verifies that the new system will function as intended when moved into the live environment, preventing unexpected service outages.
Stage 5: Post-Implementation Review
The final stage is the Post-Implementation Review (PIR). Even after the change is deployed, the process is not complete. The PIR is a retrospective analysis designed to confirm that the change met its objectives and to document lessons that can improve future performance.
The project team meets to evaluate the outcome by answering several specific questions:
- Did the change achieve the technical and business goals defined in the RFC?
- Was the project completed within the original budget and timeframe?
- Which specific actions contributed to the success of the deployment?
- What obstacles were encountered, and what steps can be taken to prevent them in future projects?
This review ensures the process remains effective over time. By documenting what worked and what did not, the organization can refine its change management IT process. This turns every project—regardless of how smoothly it went—into a source of data for future improvement.
Understanding Key Roles and Responsibilities
Effective IT change management relies on people who understand their specific duties, not just on well-drawn flowcharts. Roles must be clear so that accountability remains visible throughout the process. When duties are vague, deadlines often slip, tasks get ignored, and the entire workflow slows down.
Imagine a film crew on a set. You have a director, a producer, and actors. The movie succeeds only if every person executes their specific assignment. The same logic applies to IT updates. By defining who performs which task, you convert potential confusion into a predictable workflow. This clarity provides a significant advantage, especially since only about 34% of major change initiatives reach their intended goals (verify current success rates on research sites). The data on change management success rates highlights how much defined roles contribute to a project's survival.
Let's look at the primary participants involved in this process.
The Change Requester: The Visionary
Every update begins with a person who identifies a problem that needs solving or an opportunity for improvement. This person is the Change Requester. They do not merely fill out a form; they act as the catalyst for the entire sequence of events.
The main responsibility of the requester is to explain the reason for the change. They must document the current issue, describe the proposed fix, and outline the expected business benefits within a formal Request for Change (RFC). A successful requester often functions as a subject matter expert in their specific field—such as sales, finance, or operations. They translate department-specific needs into a technical case that the IT department can evaluate. They also help define what success looks like for the request, ensuring the technical team understands the desired outcome from a user perspective.
The Change Manager: The Orchestra Conductor
If the requester writes the music, the Change Manager serves as the conductor. This person does not necessarily play an instrument but ensures every musician stays in sync and follows the tempo. They act as the central point for all communication and logistics.
The Change Manager handles several specific tasks:
- Directing the RFC through every stage, starting from the initial submission to the post-implementation review.
- Maintaining open communication channels between the person requesting the change, the technical staff, and the business leaders.
- Verifying that every step of the internal process is followed, that documentation is accurate, and that all risks are identified.
This role requires a combination of organizational talent, clear writing, and a solid grasp of how the IT department functions. They act as the protectors of the procedure, making sure no detail is overlooked before a change moves to the next phase.
The Change Advisory Board: The Strategic Gatekeepers
The Change Advisory Board (CAB) functions as the high-level gatekeeper for the organization. This is a cross-functional group that typically includes representatives from IT, security, finance, and various business units. They meet to review and then approve or reject changes that carry a high level of risk or impact.
The CAB does not exist to slow down progress or create unnecessary hurdles. Instead, they provide a broad view of a proposed change. They look at how a change aligns with the company's long-term goals, check for potential security vulnerabilities, and ensure that the budget is used for the most valuable projects. Their approval serves as a vital checkpoint. It verifies that a change is technically sound and beneficial for the company. This collective review prevents a well-intentioned update in one department from accidentally causing a system failure in another.
The Implementation Team: The Skilled Builders
The Implementation Team consists of the technical staff who perform the actual labor. These developers, system administrators, and engineers build, test, and deploy the solution. Once the CAB provides authorization, this team transforms the plan into a functional reality.
Their duties center on technical execution. They must follow the approved specifications, conduct rigorous testing in a sandbox or staging environment, and perform the deployment during a designated maintenance window. If an update causes an unexpected outage, this team is also responsible for executing the rollback plan to restore services. Their technical skill and attention to detail determine whether the change succeeds without disrupting the business.
The following table summarizes how these roles interact to keep the process moving forward.
Table: Key Roles in the IT Change Management Process
| Role | Primary Responsibility | Key Interaction |
|---|---|---|
| Change Requester | Submits the initial Request for Change (RFC) with a clear business case. | Works with the Change Manager to refine the RFC and provide necessary details. |
| Change Manager | Manages the change lifecycle, ensures process compliance, and facilitates communication. | Coordinates with the Requester, Implementation Team, and CAB. |
| Change Advisory Board (CAB) | Assesses, prioritizes, and authorizes high-impact changes based on risk and business value. | Reviews RFCs presented by the Change Manager and provides approval or rejection. |
| Implementation Team | Builds, tests, deploys, and (if necessary) rolls back the change. | Receives the approved change plan from the Change Manager and executes it. |
With these roles clearly defined, every participant understands their specific contribution. This structure leads to a more efficient, reliable, and predictable IT environment.
Applying Frameworks Like ITIL for Better Results
Building a change management IT process from the ground up is unnecessary when established frameworks offer proven structures. The Information Technology Infrastructure Library, known as ITIL, provides a set of practices used by organizations worldwide to bring consistency to technical operations. It serves as a practical toolkit rather than a restrictive set of rules. By following these principles, teams align their workflows with a methodology that balances the need for rapid deployment with the requirement for system stability.
Adopting a framework helps establish a shared vocabulary across the department. When everyone uses the same terms and follows the same steps, the risk of miscommunication drops. This ensures that every modification to the production environment receives the appropriate level of scrutiny without creating artificial bottlenecks.

The Role of Change Enablement in ITIL 4
The current version of the framework, ITIL 4, shifted its terminology from "change control" to Change Enablement. This change reflects a move toward a more modern IT philosophy. Control often implies a static process where a gatekeeper stops progress to check for errors. Enablement, however, focuses on providing the tools and paths needed to move changes through the system safely and efficiently.
The core purpose of the Change Enablement practice is to maximize the number of successful service and product changes by ensuring that risks have been properly assessed, authorizing changes to proceed, and managing the change schedule.
This perspective acknowledges that modern IT must remain agile. The objective is not to block changes but to make them successful by identifying risks early. This approach supports fast-moving development teams while maintaining the governance required for enterprise stability. For those seeking more technical specifics, the ITIL 4 Change Enablement guide provides a look at these requirements.
Understanding the Three Types of IT Changes
ITIL organizes changes into three distinct categories based on their risk level and potential impact on the business. This classification allows organizations to use their resources effectively. Low-risk, repeatable tasks move quickly through the system, while high-impact modifications receive the oversight necessary to prevent outages.
Most organizations utilize these three main types:
- Standard Changes
- Normal Changes
- Emergency Changes
Defining these categories clearly helps teams determine which approval path to follow for any given Request for Change (RFC).
Standard Changes: Low Risk and Pre-Approved
Standard Changes cover routine, repetitive tasks that the IT team understands well. These changes follow a documented procedure that has been proven effective over time. Because the risks are known and the outcomes are predictable, these tasks are pre-authorized by management. This removes the need for a formal review for every single instance, which speeds up service delivery.
Common examples include:
- Resetting a user’s password. This is a high-frequency task with a specific, secure workflow and negligible risk to the broader infrastructure.
- Installing approved software on a new laptop. Technicians use a standard image or a verified installer, ensuring the software meets company security standards.
- Replacing a broken mouse or keyboard. This simple hardware replacement affects only one user and does not impact network services or server stability.
By pre-approving these actions, the IT department eliminates bureaucratic delays for common requests. This allows the team to focus their energy on more complex issues that require active problem-solving.
Normal Changes: Requiring Formal Review
Normal Changes involve modifications that are not routine and carry a moderate to high level of risk. These are non-emergency updates that must go through the entire change management lifecycle. The process begins with a formal submission and continues through risk assessment, technical review, and scheduling.
Because these changes can disrupt business operations, they often require approval from the Change Advisory Board (CAB). The CAB evaluates the timing of the change and the potential impact on other systems.
Examples of Normal Changes include:
- Upgrading a critical production server. This requires a detailed plan for downtime, coordination with stakeholders, and a verified rollback strategy in case the upgrade fails.
- Migrating the company’s email system to a cloud provider. Moving data for the entire organization is a high-stakes project that impacts every employee and requires significant technical oversight.
- Deploying a new feature for a customer-facing application. New code can introduce bugs or performance lag, so these deployments require testing in staging environments before moving to production.
The formal review process ensures that the team has considered every variable. It turns potential disasters into managed risks.
Emergency Changes: Urgent and Unplanned
Emergency Changes occur when the team must act immediately to resolve a critical issue. These are usually responses to major incidents, such as a security breach or a total system failure. Because the business is losing money or facing a threat, there is no time for the standard multi-day review process.
In these cases, a smaller group called the Emergency Change Advisory Board (ECAB) typically grants approval. This group has the authority to make quick decisions to restore service. While speed is the priority, the team still documents the change as it happens or immediately afterward.
Key examples include:
- Patching a zero-day vulnerability. If a security flaw is being exploited, the security team must apply a patch immediately to protect sensitive data.
- Restoring a critical database from a backup. If a primary database becomes corrupted, the IT team must initiate a recovery process to bring business services back online.
- Pushing a hotfix for a total system outage. When a service is completely unavailable, developers must deploy a fix to resolve the underlying cause of the downtime.
Even though these changes are rushed, they carry significant risk. A post-implementation review is necessary to ensure the fix was successful and to identify ways to prevent similar emergencies in the future.
Proven Best Practices for a Smooth Implementation
Knowing the theory behind a change management IT process is one thing. Putting it into practice under pressure is another. Moving from a clean plan on a whiteboard to real-world execution is where most initiatives struggle. Success involves more than just checking off stages. It requires adopting habits that avoid common failures and build actual momentum. These lessons come from teams that have managed complex IT changes and survived the experience.
Prioritize Crystal Clear Communication
Communication is the most critical factor in change management. Period. When employees are left in the dark, they often fill the silence with worst-case scenarios. That leads to resistance, confusion, and frustration. A proactive communication plan explains the what, why, when, and how of the change. Different stakeholders require different levels of detail. Your executives might only need high-level milestones, while your system administrators need granular technical specifics.
Suppose your team schedules a weekend server migration that will trigger a temporary outage. If you do not tell anyone, your customer support staff will face a wall of angry calls on Monday morning. However, if you share the timeline and the impact several days ahead of time, those support agents are prepared. They can manage inquiries with confidence, turning a potential crisis into a controlled event.
Develop a Comprehensive Rollback Plan
Hope for the best, but prepare for the worst. A rollback plan is your safety net. It is a step-by-step procedure to return everything to its previous state if the change fails. This is not about being a pessimist; it is professional preparedness. You must test your rollback plan as strictly as the change itself.
It needs to define specific triggers—such as a specific error rate or a downtime threshold—for when to stop the deployment and pull the plug. It should also outline the exact technical steps and communication protocols needed to restore normalcy. Documentation is key here. Every command and script used in the rollback must be recorded so that an engineer can follow them while under pressure without making a mistake.
A solid rollback plan turns a potential disaster into a manageable incident. It gives the implementation team the confidence to act decisively, knowing they have a clear path to restore stability if something goes wrong.
Operating without one is like flying a plane without a parachute. You might not intend to use it, but you will be in trouble if you need it and do not have it.
Implement Phased Rollouts to Contain Risk
Deploying a change to everyone at once—the "big bang" approach—is asking for trouble. A smarter strategy uses a phased rollout, where the change reaches small, controlled groups over time. This works like an early warning system. It allows you to identify and resolve issues with a small audience before they affect the entire company. You can segment this in several ways:
- Pilot Group: Start with a small, tech-savvy team that can provide detailed feedback. This group acts as your testing ground to catch bugs that did not appear in the staging environment.
- By Department: Deploy to one department at a time. For instance, you might start with Finance before moving to Marketing. This allows you to manage specific workflow interruptions without stopping the entire business.
- By Geography: Apply the change in one office or region before going global. This is particularly useful for identifying latency issues or local configuration problems that only appear in specific locations.
This approach limits the damage from unexpected problems. Issues become easier to isolate, manage, and fix without causing a company-wide shutdown.
Invest Heavily in User Training and Support
A technically perfect change can still fail if users do not know how to use the new system or feel abandoned. Training is not an afterthought; it is required for adoption. Effective training is specific. A sales team using a new CRM needs to understand lead management, while the support team must learn the new ticketing features. The instruction must relate to their daily tasks.
Support should continue after the launch. You need accessible help channels like a helpdesk, clear FAQs, or short video tutorials. Additionally, creating a feedback loop during the training phase allows you to refine your materials. If multiple users struggle with the same step, you can update your FAQs or videos to address that specific pain point immediately. This ongoing support builds user confidence and ensures that new habits stay in place after the official training ends.
How AI Is Shaping the Future of IT Change
The traditional change management IT process—built on manual checklists and gut-level decisions—is ending. A new era is already here, and Artificial Intelligence (AI) drives it. This shift moves the practice from a reactive struggle to a proactive, and often predictive, strategy.
AI acts as an intelligent assistant for the Change Manager. Instead of relying only on personal experience, managers use tools that scan years of historical data. This gives them the power to forecast the risk of a new change before a technician even submits the request.
From Reactive to Predictive
AI identifies patterns that humans often miss. By reviewing thousands of past changes, these systems learn which variables lead to success and which ones cause failures. This shifts how teams handle risk assessment.
Imagine a proposed server patch. An AI tool might flag it because the technical parameters match a change that caused a three-hour outage six months ago. That data-driven insight allows teams to rethink their execution plan and avoid a major incident. Instead of flying blind, they operate with a map built from previous successes and failures recorded in their system.
As shown in these change management trends for 2025, integrating AI is more than a slight update. It changes how organizations handle transitions, helping them increase adoption rates and reduce technical friction.
Automation and Sharper Decision Making
Beyond risk flagging, AI cleans up the daily workflow by automating administrative chores. It handles the repetitive tasks that usually bog down skilled professionals, which frees them to focus on high-level technical strategy rather than paperwork.
Current AI applications include:
- Automated Scheduling: AI analyzes company-wide calendars and historical system usage data to pinpoint the most effective, least disruptive time to roll out a technical change.
- Sentiment Analysis: These tools scan internal communications in platforms like Slack or Microsoft Teams to gauge how employees feel about a change, giving leadership a pulse on buy-in.
- Intelligent Notifications: The system can draft and send specific updates to affected groups, ensuring stakeholders get relevant information without any manual typing.
AI does not replace the Change Manager. It supports them. The technology provides data-backed evidence needed to manage complex changes with higher confidence and better results.
Staying current with these technologies prevents your process from failing. For those interested in the infrastructure behind these tools, reviewing MLOps pipelines and automation provides a look at how these systems are constructed and maintained.
Frequently Asked Questions
Practical execution often uncovers gaps that a theoretical plan misses. These common questions address the friction points teams encounter when applying change management principles.
What’s the Difference Between Change Management and Change Control?
The two terms are often used interchangeably, but they serve different functions.
Change management covers the entire scope of a transition. It focuses on the human side of the equation. This involves preparing teams for new workflows and ensuring users adopt the new system. It is the broad strategy used to move an organization from one state to another.
Change control is a specific subset of that strategy. It is the technical gatekeeping process used to manage modifications to the IT infrastructure. Change control involves the formal submission of change requests, impact analysis, and the final approval or rejection of a specific update. While change management looks at the organizational impact, change control focuses on technical stability.
How Can a Small Business Implement This Process?
Small businesses often lack the resources for a dedicated compliance department, but they still need protection against failed updates. The goal is to apply the core principles without the overhead of a massive enterprise.
You do not need a formal Change Advisory Board (CAB) when a single manager or team lead can handle approvals. Focus on these specific actions to maintain stability:
- Document every request: Use a simple spreadsheet or a basic helpdesk tool. This creates a paper trail for troubleshooting if something breaks later.
- Assess the risk: Use a three-point scale (Low, Medium, High). A five-minute conversation or a quick checklist identifies potential conflicts.
- Talk to people: Send a brief email or a chat message to affected users. Explain what is changing and when it will happen so they are not surprised.
- Always have a rollback plan: Never push a change without a clear path to revert. Test this plan before you execute the live change.
By scaling the process to your team size, you make changes predictable and safe without stalling productivity.
What Is the Single Most Critical Factor for Success?
The single most critical factor for success in any change management IT process is effective communication. A technically perfect deployment can still fail miserably if people don't understand why a change is happening, feel unprepared, or resist the new way of working.
Technical execution is a basic requirement. However, communication determines whether that work delivers value to the business. I have seen updates roll back because the users were confused by the new interface or were unaware the downtime was scheduled, rather than due to code failure.
Clear and consistent communication builds trust between the IT department and the rest of the company. It ensures the human side of the operation remains as stable as the hardware.
Ready to master the concepts behind IT certifications like ITIL and AWS? MindMesh Academy provides expert-led study guides and evidence-based learning tools to help you pass your exams and accelerate your career. Explore our courses today.

Written by
Alvin Varughese
Founder, MindMesh Academy
Alvin Varughese is the founder of MindMesh Academy and holds 18 professional certifications including AWS Solutions Architect Professional, Azure DevOps Engineer Expert, and ITIL 4. He's held senior engineering and architecture roles at Humana (Fortune 50) and GE Appliances. He built MindMesh Academy to share the study methods and first-principles approach that helped him pass each exam.