Your AWS Data Engineer Roadmap For 2026
Your AWS Data Engineer Roadmap For 2026
AWS Data Engineers do more than manage files. They serve as the technical builders behind complex data structures on Amazon Web Services. These specialists design and maintain the pipelines and infrastructure needed to convert messy, raw data into the structured formats required for business intelligence, machine learning, and generative AI. This career track merges software engineering fundamentals with deep knowledge of databases, data warehousing, and modern cloud architecture. It is a demanding role, but the professional rewards are significant for those who grasp these tools. At MindMesh Academy, we have identified the specific skills required to succeed in this field. This roadmap provides a clear path for IT professionals looking to advance their careers and master the AWS data stack through the coming year.
The AWS Data Engineer Landscape in 2026
The scope of an AWS Data Engineer's role has grown significantly. It has moved past simple ETL (Extract, Transform, Load) tasks to focus on the architecture of a company's entire data foundation. This base layer supports everything from standard business reporting to the complex data pipelines that feed modern generative AI systems. As companies manage more data at higher speeds than ever before, they need people who can build systems that are scalable and cost-effective on the AWS platform. This is a fundamental change in how businesses use their data to find a competitive advantage in their specific markets.
The career outlook for this role is strong. Data suggests that by 2026, there will be a 49% increase in data engineering positions compared to the last four years. This growth is much faster than other roles in the field, such as data analysts (12.6%) and data scientists (11.7%). These numbers show that companies have an urgent need for these technical skills. To see more about how these market forces are changing the industry, you can watch this analysis of the current data job market.
Core Responsibilities and Impact
An AWS Data Engineer is the person responsible for making sure an organization's data is available and ready for use. They take raw information and turn it into a format that data analysts and scientists can use to help the company make better decisions. Their work covers several important areas of technology and business operations:
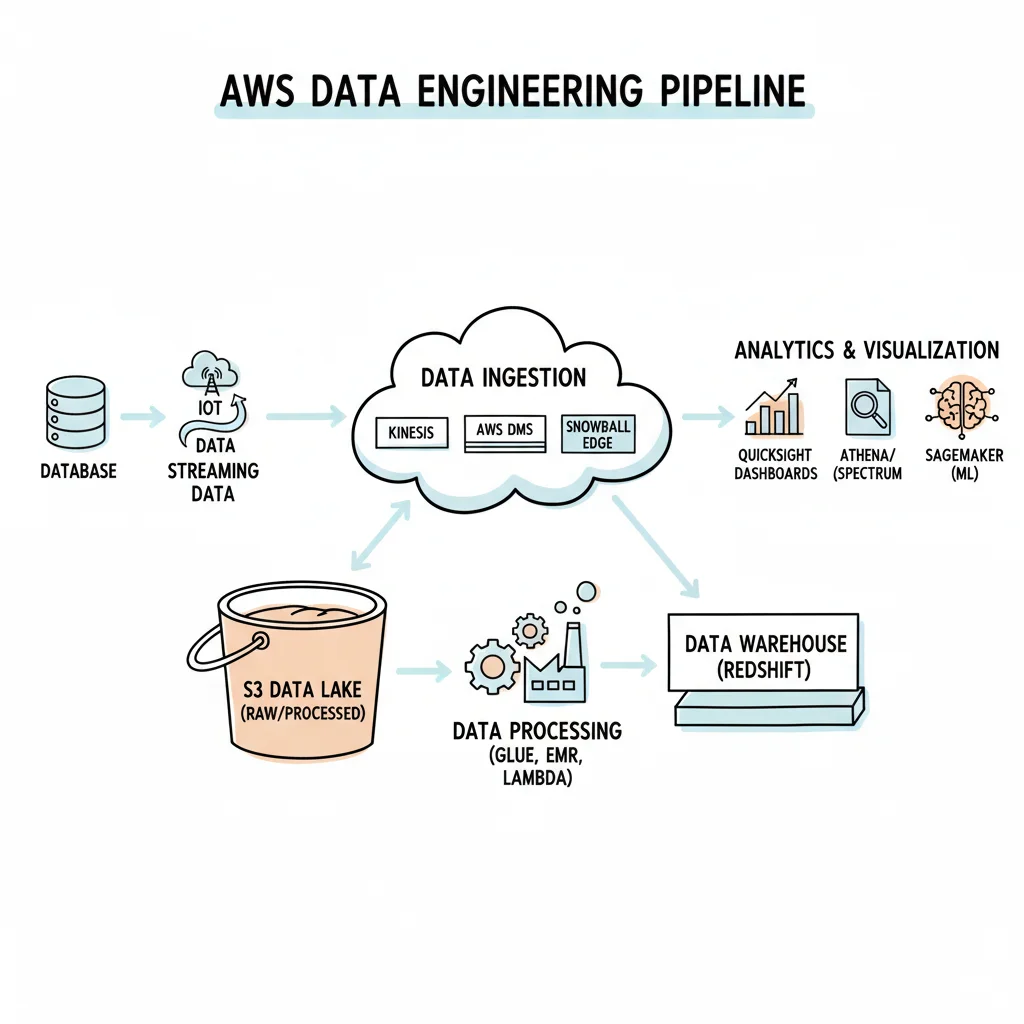
- Designing Data Pipelines: This involves building automated systems to move data from many different places into a single location. These sources include databases used for daily business, logs from software applications, or streams of data from IoT sensors. Most of the time, this data is moved into an Amazon S3 data lake, which provides a durable and scalable object storage solution for staging raw information. On AWS certification exams, you will likely see questions that ask you to pick the best ingestion tool for specific types of data based on how much there is and how fast it arrives.
- Managing Data Infrastructure: Engineers are in charge of setting up and maintaining the services that store and process data. This might include configuring Amazon Redshift to handle very large analytical queries using its massive parallel processing capabilities. They might also use AWS Glue to integrate different data sources without needing to manage servers. This serverless tool helps automate the discovery of data schemas and the preparation of data for analysis. Understanding how these tools work and how they impact the monthly AWS bill is a major part of the job.
- Ensuring Data Quality: Raw data is almost always messy or incomplete. A data engineer builds systems that check, clean, and fix data as it moves through the pipeline. This ensures that the information is accurate and can be trusted by everyone in the company. If the data is not cleaned properly, the results of any analysis or machine learning model will be wrong, a problem often called "garbage in, garbage out."
- Optimizing for Performance and Cost: Working in the cloud means that every action has a cost. A good data engineer is always looking for ways to make pipelines run faster and use fewer resources. They might change how data is stored, perhaps moving older files to cheaper S3 storage tiers, or rewrite a script to make it more efficient. This focus on saving money while maintaining high performance makes them very valuable to their teams and the broader business.
A data engineer provides value by connecting raw, messy data with the clean, organized information that businesses use to plan their future. They create the systems that allow data to flow smoothly from the point of creation to the point of analysis. They are the architects of the data paths that analysts and scientists use to do their work.
To understand how this role compares to others in a typical data team, it is helpful to look at their different goals and tools.
Reflection Prompt: Think about a time when you needed information but the data was messy or hard to find. How could an AWS Data Engineer have helped fix that problem using automated tools to turn that raw data into something useful?
Data Roles at a Glance: Data Engineer vs. Analyst vs. Scientist
| Aspect | AWS Data Engineer | Data Analyst | Data Scientist |
|---|---|---|---|
| Primary Goal | Design and maintain the systems and pipelines that move and store data. | Study structured data to find trends and help with business decisions. | Create predictive models and machine learning tools to solve complex business problems. |
| Core Skills | Python, SQL (advanced level), AWS services (S3, Glue, Redshift, Kinesis), data modeling, and distributed computing. | SQL, data visualization tools like Tableau or Power BI, and basic statistical analysis. | Python or R (advanced level), machine learning, statistical modeling, and advanced mathematics. |
| Main Tools | AWS Glue, Apache Spark, Kinesis, Redshift, Lambda, Airflow, and EMR. | Excel, SQL, Tableau, Power BI, and various business reporting software. | Jupyter Notebooks, Scikit-learn, TensorFlow, PyTorch, and Amazon SageMaker. |
| Typical Output | Working data pipelines, data lakes, and structured data warehouses. | Reports, data dashboards, and specific business recommendations. | Machine learning models, data forecasts, and new data products. |
| Salary Range (US) | $120,000 - $180,000+ (Confirm current salary data for your region on sites like Glassdoor or Indeed) | $70,000 - $110,000 (Confirm current salary data for your region on sites like Glassdoor or Indeed) | $130,000 - $200,000+ (Confirm current salary data for your region on sites like Glassdoor or Indeed) |
This table shows that the work of a data engineer is the foundation for everything else. If the data engineer does not build a reliable system, the data analyst and data scientist will not have the information they need to do their work.
Why Is This Role So Critical Now?
The demand for AWS Data Engineers is increasing because of the size and variety of data that companies now collect. Businesses are no longer satisfied with just looking at old sales reports. They want to use data from IoT devices, website clicks, and customer comments on social media to make decisions in real time. Processing this variety of data requires specialized knowledge of cloud-native tools.
An AWS data engineer has the specific skills needed to handle this large amount of data on the AWS platform. They know how to use services like Amazon Kinesis for processing data as it arrives, AWS Lambda for running code without managing servers, and AWS Step Functions to organize complex workflows into a reliable sequence. These skills allow companies to find important information and maintain a competitive edge in 2026. If you are new to the AWS platform, you can start by learning about the basic services. MindMesh Academy provides a high-level introduction to core AWS services that will help you understand the most important concepts before you move into data specialization.
Laying the Groundwork: Your Core Skillset
Before you open the AWS Management Console, you must build a strong foundation in core data engineering. A high-performing data engineer does more than navigate cloud menus; they understand the mechanics of how data moves, changes, and settles. AWS provides a massive toolset, but these services are ineffective if you do not understand programming, database interaction, and data structure design. You must know why you are choosing a specific service and how it solves a technical business problem. This section covers the essential skills that form the basis of your expertise as an AWS Data Engineer.
Get Good at Python—Really Good
Python is the primary language for modern data engineering. Knowing basic syntax is just the start. You need to be fluent in the libraries that do the heavy work in production pipelines. If you want to work effectively on AWS, two libraries are mandatory:
- Pandas: This is your primary tool for data manipulation and analysis. You must be comfortable working with DataFrames, cleaning messy datasets, handling missing values, and joining data from different sources. For example, you might use Pandas inside an AWS Lambda function to parse and reshape incoming JSON or CSV files before sending them to an S3 bucket or a database. Proficiency here means you can write efficient code that doesn't crash when it encounters an unexpected data format.
- Boto3: This is the official AWS SDK for Python. It is how your code talks to the AWS environment. Mastering Boto3 allows you to control almost any AWS service through scripts. You will use it to upload files to Amazon S3, start an AWS Glue crawler, or manage cloud resources automatically. Understanding Boto3 is what differentiates a manual operator from an engineer who builds automated, infrastructure-as-code solutions.
Practical Exercise: Build a project for your portfolio to prove these skills. Write a Python script that pulls data from a public weather API. Use Pandas to clean the response, handle any null values, and convert the data into a standard format. Finally, use Boto3 to upload that processed data—ideally as a Parquet file—into a versioned S3 bucket. This exercise tests your ability to connect local code to cloud storage.
Reflection Prompt: Identify a repetitive manual task you perform with files or spreadsheets. How could a Python script using Pandas and Boto3 automate that work?
Move Way Beyond Basic SQL
Data engineers use SQL every day. You will use it to query data warehouses like Amazon Redshift, run ad-hoc analysis with Amazon Athena, and manage relational databases on Amazon RDS. Your SQL skills must go past simple SELECT statements. To manage and transform data at scale, you need to master these advanced concepts:
- Complex Joins and Set Operations: You must know how to combine large tables without killing performance. This means understanding when to use
INNER JOIN,LEFT JOIN,FULL OUTER JOIN, andCROSS JOIN. You should also know how to useUNION,INTERSECT, andEXCEPTto combine or compare data across different result sets. These operations are the basics of data integration. - Window Functions: These are necessary for analytical queries. You will frequently need to calculate running totals, moving averages, or rank items within a group. Knowing how to use
RANK(),ROW_NUMBER(),LAG(), andLEAD()allows you to compare values across rows without complex self-joins. Exam questions often ask you to apply these functions to solve business logic problems. - Performance Tuning: Slow queries cost money and waste time. You need to know how to optimize them. This includes reading an
EXPLAINorEXPLAIN ANALYZEplan to find bottlenecks. You should understand how to create indexes, use partitioning, and choose distribution keys in a massively parallel processing environment like Redshift. A single optimized query can cut pipeline runtimes by hours and reduce compute costs. - Common Table Expressions (CTEs): Using
WITHclauses to create CTEs makes your code readable and modular. It allows you to break a massive, confusing query into smaller, logical parts. This makes your SQL easier to maintain and debug for your teammates.
Writing clean, high-performance SQL is a core requirement. It determines if a data pipeline finishes in minutes or runs for hours, which directly affects whether a business has the data it needs to make decisions.
Think Like an Architect: Data Modeling & Warehousing
Beyond writing code, an AWS Data Engineer must design how data is stored. Data modeling is the plan for your data warehouse and data lake. If your model is bad, your queries will be slow and your data will be hard to use. You must understand the core concepts that drive good architecture:
- Star Schema: This is the standard model for most data warehouses. It uses a central fact table for quantitative data, like sales totals or sensor readings. This table links to several dimension tables that provide context, such as customer names, product categories, or dates. The star schema is popular because it makes queries fast and easy for analysts to understand.
- Snowflake Schema: This is a variation of the star schema where dimension tables are normalized into even smaller tables. This saves storage space and reduces data duplication, but it makes queries more complex because it requires more joins. You need to understand the trade-offs between these two models to pass technical interviews and certification exams.
- ETL vs. ELT: This is a major shift in how we handle data.
- ETL (Extract, Transform, Load): You pull data from a source, change it using a separate processing engine, and then load it into a warehouse. This was the standard for old on-premise systems with limited storage.
- ELT (Extract, Load, Transform): You pull raw data and load it directly into a cloud data lake like S3 or a warehouse like Redshift. You then use the massive power of the cloud to transform the data where it sits. ELT is often the better choice for AWS because it lets you keep a copy of the raw data and scales better for high-volume streams.
These are not just ideas to memorize; they are the rules you use to make design decisions. You must know when a star schema is the right choice for a report or why an ELT pattern works better for a high-speed data stream on AWS. This strategic thinking is what makes you an effective engineer. Understanding how to organize data for both performance and clarity ensures that the systems you build can grow as the data volume increases. Whether you are designing a small database on RDS or a multi-petabyte warehouse on Redshift, these modeling principles remain the same. Mastery of these fundamentals allows you to use AWS services to their full potential rather than just using them as basic storage.
Mastering the Core AWS Data Services
After establishing a firm grasp of Python, SQL, and data modeling, you can begin to architect and implement reliable, real-world data solutions on the AWS platform. A major part of the AWS data engineer role involves learning how to integrate various services. Each tool is selected to perform a specific function within the data lifecycle, which moves from initial ingestion to storage, then through processing, and finally to orchestration. This lifecycle-driven strategy helps you build data pipelines that are functional, efficient, and capable of scaling as requirements change.
The demand for these technical skills is high. The global data engineering services market is expected to reach $213 billion by 2026 (verify current market projections on industry analyst sites). This growth is fueled by the creation of approximately 230-240 zettabytes of data annually. Such a massive increase in data volume places AWS experts at the center of one of the fastest-growing careers in the technology sector. For more detailed insights into this rapid market growth, refer to usdsi.org. The following AWS services build directly upon your existing Python and SQL knowledge.
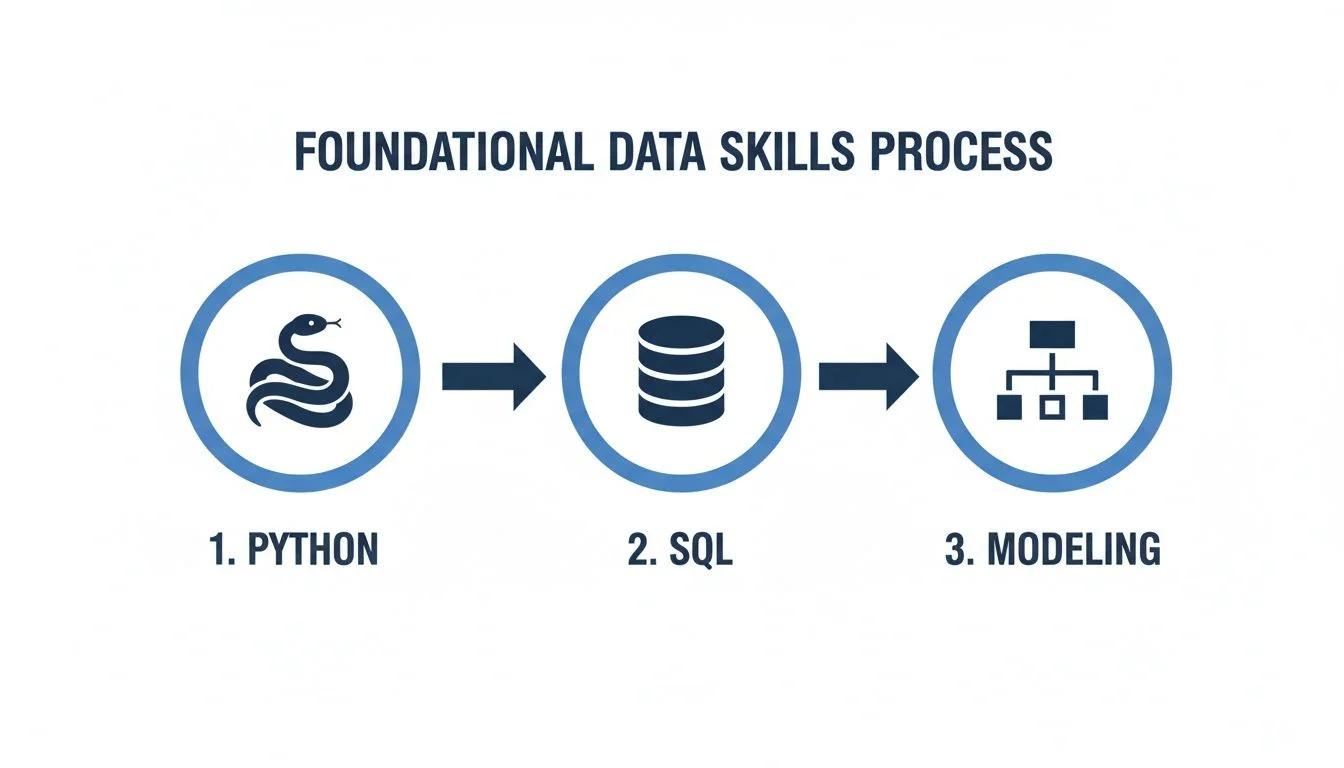 Caption: Visualizing the foundational skills: Python and SQL underpin effective data modeling, which together form the foundation for mastering AWS data services.
Caption: Visualizing the foundational skills: Python and SQL underpin effective data modeling, which together form the foundation for mastering AWS data services.
This diagram shows the logical progression of a data engineer. You start with coding and querying and then move into the architectural mindset required to assemble large-scale data systems.
Capturing Data with Ingestion Services
The first step in any data pipeline is to move data into your AWS environment securely. Your choice of an ingestion service depends on the characteristics of the data, specifically its velocity, volume, and its source. Knowing which tool to use for a specific scenario is a common requirement for certification exams.
- For Real-Time Streaming Data: When you work with high-throughput, continuous streams of information—like website clickstreams, social media feeds, or sensor data from IoT devices—AWS Kinesis is the standard tool. Kinesis includes several specific services:
- Kinesis Data Streams: This service captures and stores gigabytes of data per second. It allows for real-time processing with very low latency. For instance, an e-commerce platform might use Data Streams to power a live dashboard showing trending products by capturing every click and "add-to-cart" event as it happens.
- Kinesis Data Firehose: This is a managed service used to deliver real-time streaming data to destinations such as Amazon S3, Amazon Redshift, or Amazon OpenSearch Service. Firehose can also handle basic data transformations and format conversions before the data reaches its final destination.
- For Database Migration and Replication: If you need to perform a one-time migration or set up continuous data replication from an existing database, AWS Database Migration Service (DMS) is the primary choice. You might use this to move an on-premises MySQL database to Amazon RDS or Amazon Aurora. DMS makes it easier to sync data between different database types while reducing downtime. It maintains data integrity throughout the move and supports a wide variety of sources and targets, making it a flexible tool for modernizing legacy systems.
Storing Data for Scale and Accessibility
After data is ingested, you must place it in a storage solution that defines how easily it can be accessed, processed, and governed. The most important decision at this stage is usually whether to use a data lake, a data warehouse, or a combination of both. This architectural choice is a common theme in AWS certification design scenarios.
- Amazon S3 (Simple Storage Service) - The Data Lake Foundation: Most modern data lakes are built on Amazon S3. Because it is an object storage service, S3 provides high durability and availability along with nearly infinite scalability. It acts as a landing zone for raw, unstructured, and semi-structured data. This includes images, video files, server logs, sensor data, and JSON files. Because you can store data in its original format and define the schema later, S3 is the central component of almost every AWS data architecture. It allows you to run different types of analytical workloads without needing to define strict table structures upfront.
- Amazon Redshift - The Petabyte-Scale Data Warehouse: When you have clean, highly structured data that requires fast query performance for complex analysis, Amazon Redshift is the standard solution. This is a managed, petabyte-scale cloud data warehouse. Redshift uses columnar storage and parallel processing to return query results quickly, even when working with massive datasets. It is frequently used to power business intelligence dashboards, perform ad-hoc SQL queries, and generate complex reports.
The main architectural question is rarely whether to use S3 or Redshift. Instead, most systems use S3 and Redshift together. A modern data platform uses an S3 data lake for low-cost, flexible storage of raw data and then uses a Redshift data warehouse for curated, high-performance datasets. Understanding how these two services work together is necessary for designing effective solutions and passing AWS certification exams.
Transforming Data with Processing Engines
Raw data is rarely ready for business use in its initial state. The processing stage is where you use transformation engines to clean, filter, and enrich the data. This stage turns disparate raw material into a valuable asset. Selecting the right processing tool is a frequent requirement in certification exams.
- AWS Glue - Serverless ETL and Data Catalog: For managed, serverless ETL (Extract, Transform, Load) tasks, AWS Glue is a key service. It provides several important capabilities:
- Glue Crawlers: These tools automatically find schemas and partitions in data stored in Amazon S3 or other databases. They then populate the Glue Data Catalog. This catalog acts as a central metadata repository, making your data searchable and queryable by other services like Athena or Redshift Spectrum.
- Glue ETL Jobs: You can run Python or Apache Spark scripts to transform data without managing servers. Glue handles the resource scaling automatically, which is useful for scheduled batch jobs or event-driven processing.
- Glue DataBrew: This is a visual tool that allows analysts to clean and normalize data using a drag-and-drop interface instead of writing code. Learning how Glue integrates with the rest of the AWS platform is a major part of the AWS Certified Data Engineer - Associate exam. For a comparison of different batch tools, see our guide on AWS Glue, EMR, and Athena.
- Amazon EMR (Elastic MapReduce) - Big Data Processing: If you need more control over the computing environment, specific versions of open-source frameworks, or have extremely large workloads, Amazon EMR is the better option. EMR allows you to set up and manage clusters of EC2 instances to run frameworks like Apache Spark, Hadoop, Presto, and Hive. A typical use case for EMR is processing terabytes of application logs to identify user behavior patterns or running large-scale machine learning and graph analytics. EMR gives you the flexibility to tune performance and customize configurations for specialized applications.
Orchestration and Querying Your Data
The final part of building a data pipeline is orchestration. This involves automating the different services so they work together in a sequence. It also involves providing a way for users to query the processed data. These services are used to create production-ready solutions and appear often in practical exam scenarios.
- AWS Step Functions - Workflow Orchestration: This service acts as a coordinator for your workflows. It allows you to build multi-step data pipelines as visual state machines. Step Functions includes features for error handling, automatic retries, and parallel execution to make sure your pipelines are reliable. For example, you might create a workflow that starts an AWS Glue job, waits for it to finish, and then triggers a table refresh in Amazon Redshift or sends a notification through Amazon SNS.
- Amazon Athena - Serverless Querying for Data Lakes: Amazon Athena is a serverless tool that lets you analyze data directly in Amazon S3 using standard SQL. This is a primary tool for data lake analytics. With Athena, engineers and analysts can explore raw or structured data in S3 without moving it into a database first. This speeds up data discovery and prototyping. Athena also works directly with the AWS Glue Data Catalog to understand the structure of the data it is querying.
Your Strategic AWS Certification Path
AWS certifications are more than line items on a profile. They provide a structural framework for your technical growth. For a data engineer, a certification strategy proves you can handle specific services and architectural patterns. It shows you understand the best practices needed to keep data flowing and secure. Start with a clear view of cloud basics. If you jump into complex data exams without understanding how the cloud works, you will struggle with basic infrastructure issues later. Experienced engineers suggest learning the fundamentals before you try to build a production pipeline. A certification is a proof of practical skill, confirming that you can apply cloud theory to real-world business problems.
The Foundational Starting Point
Most professionals begin with the AWS Certified Cloud Practitioner (CLF-C02). Think of this as the basic language of the platform. It does not teach you how to build a complex ETL job, but it explains how AWS charges you for one. The exam covers the shared responsibility model, which clarifies what AWS secures and what you must protect yourself. You will study core services like compute instances, object storage, and virtual networking.
Understanding the billing console and cost explorer is vital for any engineer. Data projects often fail due to unexpected costs rather than technical errors. Knowing how to set up billing alarms or identify expensive data transfer patterns saves companies money. Passing this exam gives you the confidence to speak with developers and managers using the same technical vocabulary. It provides the base for everything that follows. Without these basics, you might struggle to understand how a data lake interacts with identity management or how a database connects to a private network.
The Core Certification for Data Engineers
Once you know the basics, move to the AWS Certified Data Engineer - Associate (DEA-C01). This exam validates the skills needed for the full data lifecycle. It focuses on the day-to-day tasks of moving, storing, and processing data. This is the primary credential for anyone focused on data pipelines. The exam tests your ability to choose the right tool for a specific problem. It is divided into four main areas that cover the work of a modern data professional.
-
Data Ingestion and Transformation (34%): This domain focuses on moving data into the cloud and preparing it for use. You will work with AWS Glue to manage ETL jobs. You might use AWS Database Migration Service (DMS) to move data from on-premises databases into an S3 bucket without taking the source system offline. For live data, you will look at Amazon Kinesis. This includes Kinesis Data Streams for low-latency ingestion and Kinesis Data Firehose for loading data into storage. You must know when to use a batch process versus a real-time stream. Choosing the wrong tool leads to high latency or unnecessary costs.
-
Data Store Management (26%): This section covers where the data lives. Amazon S3 is the primary choice for data lakes because it holds unstructured files at a low cost. You need to understand S3 storage classes, such as Standard for frequent access and Glacier for long-term archiving. Amazon Redshift handles structured data for heavy analytical queries. You should know the difference between provisioned clusters and Redshift Serverless. Amazon DynamoDB works well for NoSQL needs where you need fast, predictable performance for applications. You need to pick storage based on how often you access the data and your budget constraints.
-
Data Operations and Governance (20%): This is about making things work together reliably. You will use AWS Step Functions to coordinate different tasks in a visual workflow. This allows you to handle error retries and branching logic automatically. AWS Lake Formation helps you manage who can see which data rows or columns. This simplifies security by providing one place to manage permissions across S3 and Glue. Amazon CloudWatch monitors your pipelines so you know if a job fails immediately. You must understand how to track data lineage and how to recover if a system crashes during a transformation.
-
Data Security and Monitoring (20%): Security is not an afterthought in data engineering. You will encrypt data while it sits on a disk and while it moves over the network. The exam covers using AWS Key Management Service (KMS) to manage encryption keys. You will use AWS Identity and Access Management (IAM) to give users and services the minimum access they need to do their jobs. CloudWatch logs everything so you can audit what happened during a security event. You must know how to set up private connections between services so that sensitive data never travels over the public internet.
This certification is not a test of simple memorization. It assesses your ability to apply knowledge to solve problems. Exam questions use scenarios where you must identify the most efficient, secure, or scalable solution. You might be asked to choose between different types of EMR clusters or determine the best way to partition data in S3 to improve query speed.
Key Takeaway: The AWS Certified Data Engineer - Associate exam mirrors real-world challenges. Focus on understanding why certain services are chosen for specific scenarios. Do not just learn what the services are; learn how they interact under pressure.
Broadening Your Architectural Perspective
The Data Engineer cert is your main goal, but the AWS Certified Solutions Architect - Associate (SAA-C03) helps you see the bigger picture. It forces you to think about how systems survive failures. Data pipelines do not exist in isolation. They live inside Virtual Private Clouds (VPCs) and connect to various compute resources. This certification teaches you to design systems that are resilient and cost-effective.
For a data engineer, an architectural mindset is a major advantage. It helps you build pipelines that grow as the company grows. You will learn about Elastic Load Balancing and Auto Scaling. You will study how to use Amazon Route 53 for DNS and how to deploy CloudFront for global content delivery. If an AWS region has an outage, does your data pipeline stop? A solutions architect knows how to build a multi-region setup to keep things running. This knowledge helps you design data solutions that integrate with the rest of the company's infrastructure. You can find study materials at MindMesh Academy to help you prepare for these tests.
AWS Certifications for Data Engineers: Your Learning Pathway
This table helps you decide which certification matches your current skill level and your next career move.
| Certification | Focus Area | Ideal For | Key AWS Services Covered |
|---|---|---|---|
| Cloud Practitioner | Basic cloud concepts, security, billing, and global infrastructure. | Newcomers to the cloud or those in non-technical roles. | IAM, S3, EC2, VPC, RDS, Lambda, DynamoDB, CloudWatch, Billing |
| Data Engineer - Associate | Pipeline design, data transformation, storage management, and monitoring. | Current or aspiring data engineers building cloud data systems. | Glue, Kinesis, Redshift, S3, DMS, Step Functions, Athena, EMR |
| Solutions Architect - Associate | General system design, high availability, and cost-optimized architecture. | Engineers who want to understand broad AWS design patterns. | EC2, VPC, S3, IAM, Route 53, Lambda, ELB, Auto Scaling, RDS |
View your certification path as a career accelerator. Start with a solid cloud foundation to understand the environment. Then, achieve mastery in core data engineering skills to handle the technical work. Finally, broaden your perspective with architectural insights to design systems that last. This method prepares you for more than just a test; it builds the practical expertise that employers want. A certified engineer who understands both the data and the underlying infrastructure is much more effective in a production environment.
Building Projects That Get You Hired
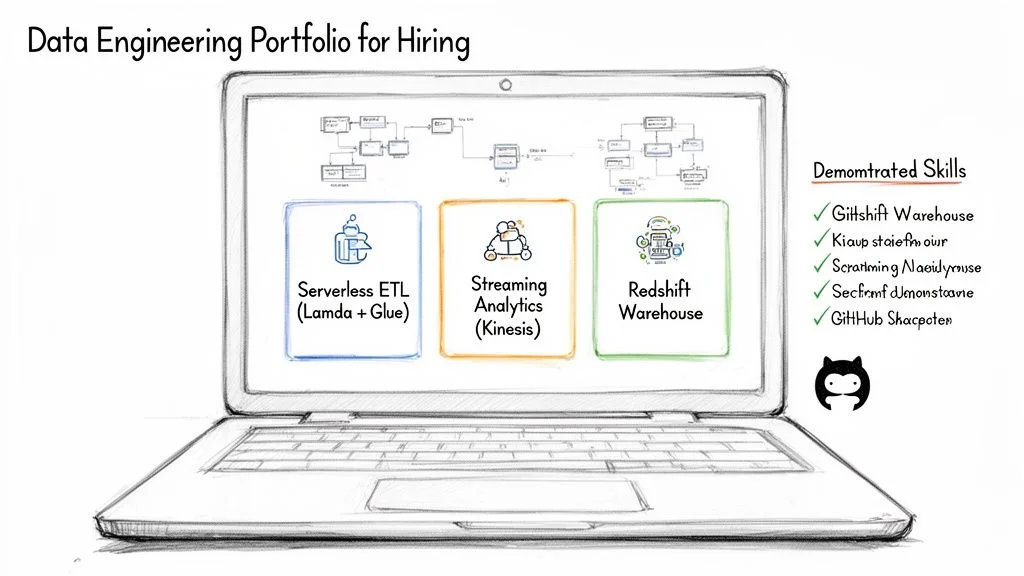 Caption: A compelling data engineering portfolio showcases practical skills through projects like serverless ETL pipelines, real-time streaming analytics, and robust data warehouse solutions.
Caption: A compelling data engineering portfolio showcases practical skills through projects like serverless ETL pipelines, real-time streaming analytics, and robust data warehouse solutions.
While certifications are useful for clearing initial resume filters, a solid portfolio of hands-on projects is what actually secures a job offer. This is where you move beyond theory and provide proof of your ability to design, build, and fix real-world data systems. Your goal is not to copy a simple tutorial. Instead, you should focus on building end-to-end systems that you can explain in detail during an interview. You must be ready to talk about why you picked certain architectures, the specific technical hurdles you faced, and the logic behind your fixes. A recruiter wants to see that you can handle the unpredictable nature of live data environments.
Project Idea 1: Serverless ETL Pipeline
A serverless ETL pipeline is a great first project. It shows you can build scalable, cost-effective data tools without managing underlying servers. This is a skill many companies want because it reduces operational costs and complexity. This project shows that you understand how cloud-native tools work together to move data from a source to an analytical store.
Scenario: Your task is to collect user clickstream data from a web application. You need to clean and transform the raw data before saving it into a data lake where analysts can run queries against it.
Proposed Architecture:
- Ingestion (API Gateway & Lambda): Start by setting up an Amazon API Gateway with a REST endpoint. This gateway accepts raw JSON clickstream data sent from the web app. Once the data arrives, the gateway triggers an AWS Lambda function to start the processing flow.
- Processing (Lambda & Pandas): The Lambda function uses Python to handle the core transformation logic. You will use libraries like Pandas to check the data for errors, remove duplicates, and change the format of messy JSON strings into structured tables. This part of the project highlights your ability to write clean, functional Python code for data engineering.
- Storage (S3 & Parquet/Partitioning): After cleaning the data, save it into an Amazon S3 bucket. You should use a columnar format like Parquet to save space and speed up queries. Organize the data using a date-based folder structure, such as
s3://your-bucket/clickstream/year=YYYY/month=MM/day=DD/. This structure is a standard industry practice that makes tools like Athena run much faster while lowering costs. - Cataloging (AWS Glue Crawler): Set up an AWS Glue Crawler to run on a schedule. This crawler scans your S3 bucket to figure out the schema of your Parquet files and updates the AWS Glue Data Catalog. This step makes your data easy to find and ready for tools like Amazon Athena or Amazon Redshift Spectrum.
Building this system shows you have a firm grip on serverless tech, data processing rules, and the best ways to organize a data lake.
A carefully documented GitHub repository does more than just hold code; it builds a story around your ability to solve technical problems. Your
README.mdshould explain the reasoning behind your architectural choices, rather than just listing the steps you took.
Project Idea 2: Real-Time Streaming Analytics
Once you show you can handle batch data, the next move is to work with data in motion. A streaming analytics project proves you can provide insights the moment events happen. This is a vital skill for companies that need to detect fraud, monitor servers, or track social media trends as they occur.
Scenario: Build a pipeline that looks at a live stream of social media posts. The system should perform sentiment analysis to find immediate trends or customer service issues.
Proposed Architecture:
- Stream Ingestion (Kinesis Data Stream): Use a Python script to act as a data producer. This script sends simulated social media posts—usually JSON objects with text and timestamps—into an Amazon Kinesis Data Stream. This acts as your high-speed entry point for the data.
- Transformation and Delivery (Kinesis Data Firehose & Lambda): Amazon Kinesis Data Firehose reads from the stream. You can configure Firehose to group records together and send them to an AWS Lambda function. This function runs the sentiment analysis. You might use a basic NLP library or a pre-trained model to score each post as positive, negative, or neutral.
- Analytics & Storage (S3 & OpenSearch): Firehose then sends the data to two places. First, it goes to Amazon S3 for long-term storage and later use. Second, it goes to an Amazon OpenSearch Service cluster. This allows you to build a live dashboard that visualizes sentiment scores in real time.
This setup shows you can build low-latency systems that provide immediate value to a business. To see more examples and gain more experience, you can look at different inscriptive projects.
Documenting Your Work for Maximum Impact
After you finish building a project, you must present it well. A folder full of code on GitHub isn't enough to impress a hiring manager on its own. You need to explain what you did and why it matters. For every project, write a detailed README.md file that acts as both a summary for managers and a guide for other engineers. Your documentation should include the following sections:
- A clear overview of the project that describes the business problem you solved and why the solution is useful.
- A high-level diagram showing how the AWS services connect. You can use simple drawing tools or even text-based diagrams to show the data flow.
- Step-by-step setup instructions so someone else can run your code. Mention any specific settings or permissions they need to configure in their own AWS account.
- Samples of your most important code. Explain what these snippets do and why you wrote them that way, especially if you found a way to make the code faster or cheaper.
- A "Challenges and Lessons" section. Talk about the bugs you found or the parts of the AWS configuration that were difficult to get right. Explaining how you fixed these problems shows that you have the persistence and skill to handle real engineering tasks.
Writing this way changes your project from a simple script into a professional case study. It proves you are not just someone who can write code, but a thoughtful AWS Data Engineer who understands the bigger picture of cloud architecture. Your portfolio should be a reflection of your growth, showing that you can take a messy set of requirements and turn them into a working, documented system.
Getting Ready for Your Data Engineer Interview
Once you have built your technical skills and organized your project portfolio, you face the interview. This stage evaluates your technical knowledge and your ability to solve problems under pressure. You will encounter a mix of technical questions and behavioral scenarios designed to see how you function within a team. Most technical assessments focus on your ability to use Python, SQL, and AWS architecture. You should prepare for live coding tasks, whiteboard system design sessions, or detailed discussions about your past work. Interviewers care less about finding a perfect solution on your first attempt. They want to see a clear, logical approach, readable code, and a solid explanation of your technical choices.
Tackling the Technical Questions
The technical round determines if you can apply theoretical concepts to actual business problems. It serves as a practical test of your engineering skills.
- Python: You might need to write a script that parses and cleans data from JSON or CSV files. Be ready to explain how to use the Boto3 library to manage AWS resources. Common tasks include automating S3 file uploads, managing EC2 instances, or triggering AWS Glue jobs through code.
- SQL: Expect to write queries that use multiple joins, window functions like RANK() or LEAD(), and common table expressions (CTEs). You may be asked to look at a slow query and suggest improvements. Be ready to discuss indexing strategies, partition pruning, and how to avoid unnecessary data scans by filtering early in the process.
- AWS Architecture (System Design): This portion tests your ability to build systems. A common prompt asks you to design a pipeline for real-time clickstream data that feeds into an operational dashboard. You must explain how to integrate services like Amazon Kinesis for ingestion, AWS Lambda for processing, and Amazon S3 for storage. You should also mention how AWS Glue and Amazon Redshift or Athena fit into the analytical layer while maintaining security.
During these discussions, think out loud. Explain your reasoning and the trade-offs you consider. For example, explain why you might choose Amazon Kinesis when you need low-latency streaming instead of Amazon SQS for simple message queuing. Compare using a serverless Lambda function against a persistent EC2 instance for specific event-driven workloads. Discussing cost versus performance or complexity versus ease of maintenance shows that you think like an architect rather than just a coder.
Explaining the logic behind your technical choices often matters more than writing error-free code. It shows you can make strategic decisions rather than just following a set of instructions.
Nailing the Behavioral Questions
Behavioral questions help hiring managers understand how you work with others and handle stress. Companies want engineers who can troubleshoot effectively and learn from mistakes. Many interviewers use the STAR method to structure these questions. This involves describing the Situation, the Task you needed to complete, the Action you took, and the Result of your efforts. Prepare stories from your projects or previous jobs that cover these topics:
- Failure and Recovery: Describe a time a data pipeline failed in production. Explain how you diagnosed the error, what you did to fix it immediately, and the steps you took to make sure it did not happen again.
- Complex Projects: Walk the interviewer through a difficult data project. Detail your specific role, the obstacles you encountered, and how you reached the final goal.
- Communication: Tell a story about working with a non-technical manager or client to define data requirements. Explain how you translated their business needs into technical specifications and how you kept them informed throughout the process.
Structuring your answers this way makes your accomplishments clear and shows you have the necessary soft skills for a professional role. Preparing for these interviews requires effort, but the financial payoff is significant. AWS data engineers are in high demand. Median annual salaries are approximately $131,000 (verify current market rates on sites like Glassdoor or Payscale). Experienced senior positions often pay $171,000 or more. Lead specialists with expertise in specific areas can achieve higher figures and often have the option to work remotely. You can find more details on these career trends and salary data at refontelearning.com.
Answering Your Top Questions About Being an AWS Data Engineer
Starting a specialized career path as an AWS Data Engineer leads to many questions about the daily realities of the role. These answers address frequently asked questions to provide clarity and practical details for those looking to enter the field.
How Much Coding Do I Really Need to Know?
You need a high level of coding proficiency, though your focus differs from that of a software engineer. A strong command of both Python and SQL is mandatory. These are the tools you will use every day to build and maintain data systems.
- Python: This language serves as the main engine for automation, data transformation, and integration tasks. You will use Python to script ETL jobs with PySpark within AWS Glue or Amazon EMR. You will also use it to automate cloud interactions through Boto3 and develop serverless functions with AWS Lambda. Focus on using data manipulation libraries like Pandas, working with API interactions, and using the AWS SDK.
- SQL: This is the universal language for interacting with data. You will spend a large portion of your time writing complex queries, performing transformations, and improving performance within services like Amazon Redshift, Amazon Athena, and Amazon RDS. Your SQL skills must include a firm grasp of window functions, common table expressions (CTEs), and query tuning.
While your daily work may not involve algorithmic challenges like those found in competitive programming, the ability to write clean, efficient, and well-documented code is essential. Your code must be maintainable so that others can modify and scale your data pipelines as the needs of the business grow.
Can I Really Become an AWS Data Engineer With No Experience?
Entering the field of AWS Data Engineering without a professional background is difficult, but you can achieve it with a structured plan and consistent effort. You must first build a foundation in the technical basics: Python, SQL, and the core concepts of cloud computing on AWS.
Your most important tool for finding a job will be a carefully built portfolio of personal projects. These projects must prove you can apply what you have learned to solve actual data problems. Adding certifications, especially the AWS Certified Data Engineer - Associate, helps validate your knowledge and makes it more likely that your resume will pass through initial screening filters. Many people start their careers in related roles. Working as a Data Analyst, Business Intelligence Developer, or Junior Database Administrator can provide the professional context needed to move into a full data engineering role later.
Which Is More Important: Certifications or a Project Portfolio?
This question is frequently debated. The truth is that certifications and portfolios play different roles, and they work best when used together. A certification, such as the AWS Certified Data Engineer - Associate, acts as a signal to recruiters. It shows that you understand the AWS platform and know the correct terminology. It helps your application survive the initial screening process where resumes are often filtered by automated systems.
A project portfolio is what proves you can actually perform the tasks required by the job. It provides evidence that you can apply theory to fix real problems. In a technical interview, a strong portfolio that you can explain in detail usually carries more weight than a certificate alone. The best strategy is to build your projects at the same time you study for your certification. This hands-on work makes the exam concepts easier to remember and gives you concrete experience to talk about. For a better understanding of what companies look for during the hiring process, you can review Data Engineer Interview Questions and Answers.
A certification helps your resume get noticed. A strong project portfolio is what convinces a hiring manager that you are competent. The most effective strategy combines both: build projects as you prepare for your exam so that your practical skills match your theoretical knowledge.
So, What Does a Typical Day Actually Look Like?
The role of an AWS Data Engineer is active and changes daily. You will spend your time developing new systems, monitoring existing ones, and collaborating with other teams. No two days are exactly the same, but most follow a general pattern involving maintenance, development, and troubleshooting.
- Morning: Monitoring and Maintenance: Your day usually starts by checking the health of your existing data pipelines. You will use Amazon CloudWatch to check logs and metrics or the AWS Step Functions console to verify that overnight data transfers finished without errors. If a pipeline failed or an alert was triggered, you must fix it immediately to ensure data is available for the business.
- Mid-day: Development and Focused Work: This is the time for technical creation. You might spend several hours writing PySpark code for a new pipeline in AWS Glue or configuring a cluster in Amazon EMR. You could be designing logic to clean raw data or building new ingestion paths using Amazon Kinesis or the AWS Data Migration Service (DMS). This work requires deep concentration and testing to ensure the data flows correctly and stays accurate.
- Afternoon: Collaboration and Troubleshooting: The later part of the day often involves working with others. You might meet with data scientists to hear about their data requirements or help stakeholders understand a new data model. You could also spend time in Amazon Redshift optimizing a query that is using too many resources or debugging a pipeline failure from earlier. Regular activities also include team stand-ups and reviewing code written by your peers to ensure quality standards are met.
Ready to turn this roadmap into reality? At MindMesh Academy, we provide study guides and practice exams using methods like Spaced Repetition to help you master AWS and earn your certification. Start your path with us today and build the skills required to get hired. Find out more at AWS Cloud Practitioner Practice Exams.
Ready to Get Certified?
Study for the current exam using high-quality materials at MindMesh Academy:

Written by
Alvin Varughese
Founder, MindMesh Academy
Alvin Varughese is the founder of MindMesh Academy and holds 18 professional certifications including AWS Solutions Architect Professional, Azure DevOps Engineer Expert, and ITIL 4. He's held senior engineering and architecture roles at Humana (Fortune 50) and GE Appliances. He built MindMesh Academy to share the study methods and first-principles approach that helped him pass each exam.