Problem Management vs Incident Management: Complete Guide
Incident Management vs. Problem Management: A Comprehensive Guide for IT Professionals
In IT service management (ITSM), distinguishing between incident management and problem management is vital for operational success. While many confuse these two practices because both aim for service stability, they serve different purposes. Incident management is reactive. It focuses on restoring a disrupted service as fast as possible to minimize downtime. Problem management is proactive. This discipline focuses on identifying and eliminating the root causes behind incidents to stop them from happening again.
The fire department analogy clarifies this well. Incident management is the crew rushing to put out a blaze to minimize immediate damage. Problem management is the fire marshal investigating the cause once the fire is out to implement safety measures that prevent future fires. For IT professionals pursuing certifications like ITIL, CompTIA, or the PMP, understanding these distinct but linked disciplines is foundational. Mastery of both ensures that short-term fixes do not overshadow long-term stability and system health.
Understanding The Core Difference
 Caption: Incident Management (left) focuses on immediate crisis, while Problem Management (right) tackles the underlying cause.
Caption: Incident Management (left) focuses on immediate crisis, while Problem Management (right) tackles the underlying cause.
Incident management and problem management serve different purposes within the IT Service Management (ITSM) framework. Incident management prioritizes speed and efficiency. Its main goal is to restore services to their normal state with minimal delay. Teams measure success by how quickly they resolve a service outage or performance drop. This speed directly impacts user satisfaction and the ability of a company to meet Service Level Agreements (SLAs).
Problem management uses a more deliberate approach. Instead of rushing to fix an immediate crisis, it identifies the reason behind recurring or major incidents. The goal is not a temporary patch but a permanent solution that improves the stability and performance of IT services. This focus reduces technical debt and makes systems more reliable over time.
To see these concepts in a real-world setting, consider an e-commerce platform that experiences intermittent crashes during a high-traffic sale event.
-
Incident Management in Action: The on-call operations team receives an alert about a service interruption. Their priority is to get the website back online right now. They might restart server instances in AWS or Azure, roll back a recent software update, or move traffic to a different server cluster. Success is primarily measured by Mean Time To Resolve (MTTR). The team stops the bleeding so customers can finish their purchases, even if the technicians do not yet know why the failure happened.
-
Problem Management in Action: After the site crashes for the third time in one month, the team opens a formal problem record. They shift away from reactive fixes to conduct a thorough investigation. Technicians examine server logs for error patterns, review performance metrics for spikes in resource usage, and analyze application traces to find the root cause. This process involves working with software developers to look at code changes or with infrastructure teams to check network settings for errors.
In this scenario, the investigation finds a memory leak in a new feature. The leak only causes a crash when the number of concurrent users reaches a specific threshold. The problem management team then coordinates a permanent fix by writing, testing, and applying a code patch. This work ensures the crash never happens again, which prevents future revenue loss and protects customer trust.
IT professionals preparing for certifications should understand how these processes integrate into a service strategy. You can see how these roles connect in our guide on What is ITIL Service Management Explained.
Key Takeaway: Incident management fixes the symptom (the website is down), while problem management cures the disease (the memory leak causing the crash).
Incident Management vs Problem Management At a Glance
The following table clarifies the differences by comparing their goals, focus, and standard activities. This snapshot helps distinguish the two roles.
| Attribute | Incident Management | Problem Management |
|---|---|---|
| Primary Goal | Restore service immediately | Prevent incidents from recurring |
| Focus | Reactive; speed and efficiency | Proactive; analysis and prevention |
| Timeline | Short-term; immediate response | Long-term; ongoing investigation |
| Core Activity | Triage, diagnosis, and resolution | Root Cause Analysis (RCA) |
Neither discipline works effectively alone. Organizations following ITIL 4 balance the urgent need for service restoration with the strategic requirement of preventing future disruptions. This balance creates a stable and resilient IT environment.
Comparing Strategic Goals and Business Impact
While both incident and problem management contribute to service stability, they operate on different timelines with specific business outcomes. Incident management acts as a tactical defense. It is immediate and focuses on maintaining current operations.
The primary goal is to resolve service disruptions as fast as possible to reduce total damage. Every minute of downtime leads to financial losses and can damage customer trust. It also risks breaching contractual Service Level Agreements (SLAs). For professionals like Project Managers with a PMP or Cloud Architects holding AWS or Azure certifications, knowing this immediate impact is essential for risk assessment and business continuity. The strategic value of incident management is clear: it protects current revenue and maintains operational integrity.
Problem management handles a different timeline. It moves beyond the immediate workaround to ensure that the same issues do not keep coming back. By investigating and removing root causes, teams reduce the total number and severity of recurring incidents. This shifts the organization away from constant firefighting and toward a proactive state of fireproofing services. This transition builds operational resilience, providing a strategic advantage for any business that relies on its IT services.
This infographic shows the connection between these two functions:
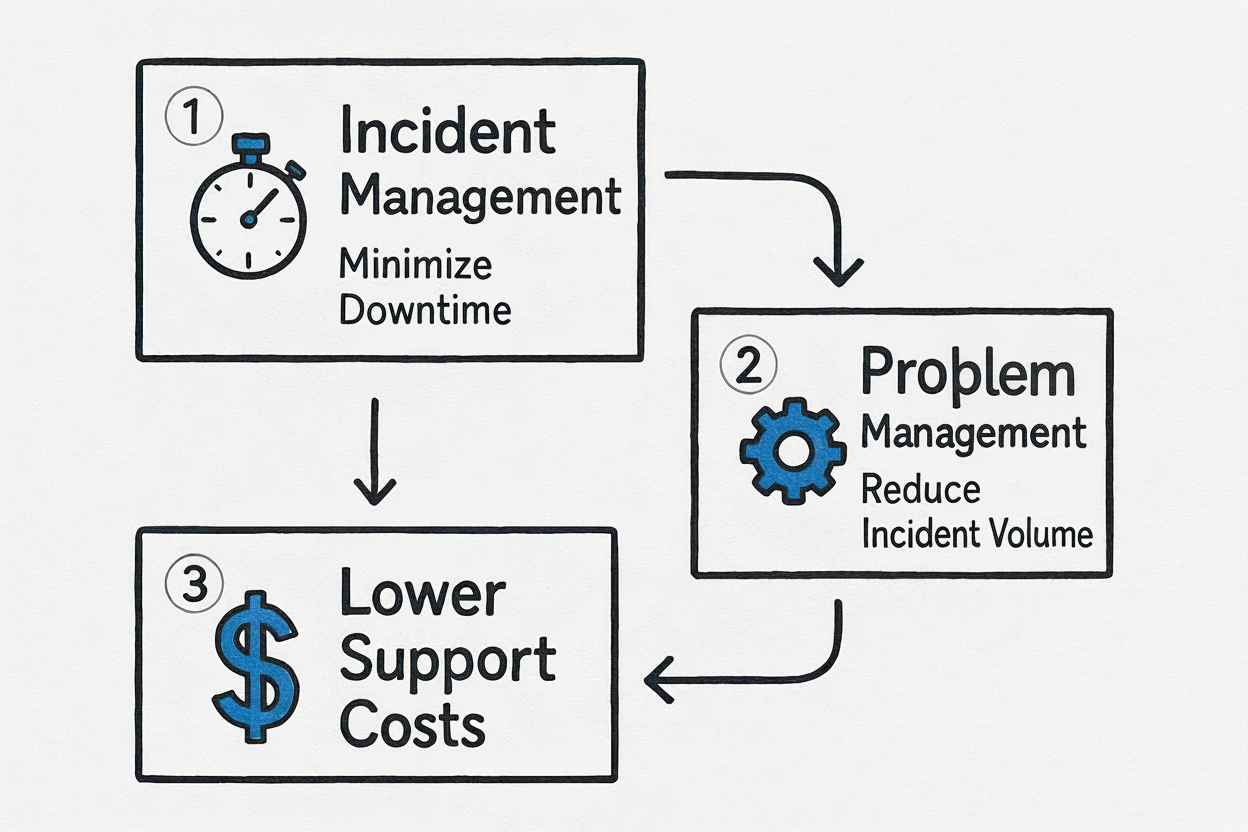 Caption: The strategic flow from immediate incident resolution to long-term problem prevention, leading to significant cost savings.
Caption: The strategic flow from immediate incident resolution to long-term problem prevention, leading to significant cost savings.
As the visual shows, containing damage is the first step. However, problem management creates lasting value by breaking the cycle of reactive fixes. This eventually drives down long-term support and operational costs.
The Shift from Reactive to Proactive Value
Understanding this distinction is vital for IT leaders when they justify budgets or allocate staff. The results of incident management are immediate and easy to measure. Metrics like Mean Time To Resolve (MTTR) show exactly how fast services are restored. This metric is a direct indicator of how well the team is stopping financial losses during an outage.
The impact of problem management takes longer to see but provides more value over time. It delivers:
- Reduced Support Costs: If you stop recurring incidents, IT teams spend less time on repetitive troubleshooting tasks. This lets them focus on development work or other strategic initiatives that provide more value to the organization.
- Increased System Reliability: By fixing underlying flaws, services become more stable and predictable. This builds user satisfaction and increases the trust stakeholders have in the IT department.
- Prevention of Major Outages: Often, a single unresolved problem is the hidden cause of many small incidents. Finding and fixing that issue early prevents a total system failure or a data breach.
The ITIL (Information Technology Infrastructure Library) framework separates these two functions for a reason. As shown in the ITIL 4 guidelines, keeping these processes distinct prevents the team from prioritizing a workaround over a permanent solution. This approach ensures that an organization does not sacrifice long-term service health for short-term stability. You can examine these ITIL guidelines to see how they work in different contexts. For those preparing for certifications, MindMesh Academy provides detailed study materials and practice tests for the ITIL 4 Foundation exam.
Key Insight: Incident management protects current operations, while problem management builds and secures resilience for the future.
Grasping these goals helps IT leaders build a better service model. One process manages the present to ensure continuity. The other builds a stable and less expensive future for the organization.
A Tale of Two Playbooks: Workflows and Processes
 Caption: Incident Management follows a rapid, linear path, while Problem Management follows a cyclical, in-depth investigation.
Caption: Incident Management follows a rapid, linear path, while Problem Management follows a cyclical, in-depth investigation.
To understand the operational differences between problem and incident management, you must examine their workflows. Each follows a specific playbook designed for a particular goal. One is built for speed. The other focuses on technical depth.
The incident management process is a high-stakes sprint. The urgency to restore service drives every action. In contrast, the problem management process is a methodical, iterative investigation. This is not just a minor difference in how teams work. It defines their very nature. Incident management aims to get systems operational immediately. Problem management is built to pause, investigate thoroughly, and find the underlying reasons why failures occur.
The Incident Management Lifecycle: A Race Against the Clock
When a service disruption occurs, the incident management workflow activates. This process is reactive. It focuses on speed because every second of downtime costs the business money and creates user frustration. Time is the primary metric here. The process begins as soon as the team detects a service disruption.
From that moment, the team follows a rapid, streamlined sequence of steps:
- Detection and Logging: The team identifies an incident. This often happens through automated monitoring alerts in tools like AWS CloudWatch or Azure Monitor. It can also start with a user report or a call to the service desk. The technician logs the incident into an ITSM system. This creates a record of the event and establishes a single source of truth for the response team.
- Categorization and Prioritization: The technician classifies the incident as a "network outage," "application error," or "security breach." They assign a priority level based on business impact and urgency. A critical system failure that stops key business functions—a Priority 1 incident—triggers an immediate response from all necessary teams. A minor cosmetic issue on a website might be scheduled for later.
- Initial Diagnosis: Front-line support teams perform a quick assessment. They want to understand the immediate symptoms. The objective is to find a known workaround or a simple fix. They do not look for the root cause at this stage. This phase requires the diagnostic skills found in the CompTIA A+ (220-1201/220-1202) or Network+ (N10-009) certifications.
- Escalation (If Needed): If the initial diagnosis does not produce a fix, the team escalates the ticket. They move it to specialized groups like database administrators, network engineers, or application developers. These experts have the technical knowledge required to solve complex service failures.
- Resolution and Recovery: The technical team implements a fix to restore the service. This could be a server reboot, a configuration rollback, or a documented workaround. The team cares only about restoring functionality to the end user.
- Closure: Once the service is stable and the users confirm the issue is resolved, the team formally closes the incident ticket.
The entire lifecycle centers on containment and rapid restoration. For a detailed breakdown of this process, our study guide on the ITIL 4 Foundation: Incident Management explains these steps in a format designed for ITIL certification candidates.
The Problem Management Workflow: An Investigative Analysis
Problem management often starts where incident management ends. This happens when incidents are severe, happen repeatedly, or suggest a systemic flaw. This process is proactive and analytical. The team wants to prevent future outages. They do not face the same immediate time pressure that defines incident management.
The core of problem management is shifting the organizational mindset from "What broke and how do we fix it now?" to "Why did it break and how do we stop it from ever breaking again?"
The problem management workflow is structured as a detailed forensic investigation:
- Problem Detection: A problem is identified by looking at incident trends. If a specific server crashes five times within a single month, it is no longer just a series of random incidents. It is a systemic problem that requires an investigation. Proactive monitoring tools can also flag these patterns before they cause a full service outage.
- Problem Logging and Categorization: The team creates a dedicated problem record. They link all related incident tickets to this record. This gives the investigation team all the historical data and context they need in one central location.
- Root Cause Analysis (RCA): This is the core of the process. The team uses analytical techniques like the "5 Whys," Ishikawa (fishbone) diagrams, or Fault Tree Analysis. They look past the symptoms to find the fundamental technical cause. This phase requires the logical reasoning skills taught in PMP or advanced ITIL modules.
- Identifying a Workaround: While the team builds a permanent solution, they document a temporary workaround. This is essential for the incident team. It allows them to resolve new, related incidents faster and more consistently while the final fix is being developed.
- Creating a Known Error Record: Once the team confirms the root cause and establishes a workaround, they create a Known Error record. This is stored in the Known Error Database (KEDB). This repository serves as a knowledge base for the entire service desk, which improves resolution times for future incidents.
- Implementing a Permanent Fix: Finally, the problem team works with developers, operations, and security teams to design and deploy a permanent solution. This step removes the root cause entirely. It typically goes through a formal change management process to ensure the implementation is controlled and successful.
Establishing these different operations is necessary for IT service maturity. By separating these two workflows, organizations can address the immediate need to restore service while also building more stable systems for the future.
Comparing Roles and Required Skill Sets
 Caption: Different mindsets and skills define the distinct roles in incident (left) and problem (right) management.
Caption: Different mindsets and skills define the distinct roles in incident (left) and problem (right) management.
Effective IT processes rely on the people who execute them. When you compare incident management to problem management, the teams involved show the most obvious differences. Their daily responsibilities, technical strengths, and professional mindsets vary because their missions are separate. One group focuses on the immediate crisis, while the other focuses on the long-term health of the technical environment.
Incident management teams act as the first responders for an organization. They operate well under pressure. Their performance is measured by speed, quick decisions, and the ability to limit damage to operations. Problem management teams are investigators. They prioritize logic, analytical depth, and the persistence required to find the source of a failure.
The Frontline Responders in Incident Management
Roles in incident management focus on quick action, team coordination, and clear updates. These professionals deal with critical failures as they happen. They work in high-stakes environments where fast thinking keeps the business running.
- Service Desk Analyst: This person is the first contact for users facing technical trouble. They handle triage and log every incident. They perform initial diagnostics using skills often covered in the CompTIA A+ (220-1201/220-1202) exams (verify current exam codes and pricing on the vendor site). Their communication skills are essential. They must collect facts from users who might be frustrated and then pass those details to the right technical teams.
- Incident Manager: When a major outage occurs, the Incident Manager takes command. This role focuses on leadership and crisis communication rather than hands-on technical repairs. They serve as a central coordinator for different teams. They remove obstacles and keep stakeholders, from executives to end-users, informed of progress. This position requires strong leadership and the ability to make fast decisions under stress, similar to a project manager handling a sudden project failure.
These roles are reactive. Their only goal is to return services to a normal state as fast as possible. They focus on the "now" to ensure the business does not lose more time or money than necessary.
Key Insight: An Incident Manager aims to restore service using any effective method available. They often choose a temporary workaround instead of waiting for a permanent fix. They handle the immediate emergency rather than the technical root cause.
The Investigative Experts in Problem Management
Problem management requires a different type of professional. These individuals are patient and methodical. They are analytical thinkers who look at the big picture. Their success is not measured by how many minutes it takes to close a ticket. Instead, they are judged by the long-term stability and reliability they build into the IT infrastructure.
The following roles are central to this investigation process:
- Problem Manager: This person manages a problem from the moment it is identified until a permanent fix is in place. The Problem Manager leads Root Cause Analysis (RCA) meetings. They make sure the service desk has documentation for known errors and work with developers to implement lasting solutions. They need strong logic and the ability to find patterns in large sets of incident data. They must stay focused on long investigations that may last weeks—a trait highly valued in ITIL or PMP environments.
- Subject Matter Experts (SMEs): A Problem Manager does not work alone. They rely on SMEs, such as senior engineers, system architects, or software developers. These experts have the deep technical knowledge required for the investigation. They provide the technical strength to diagnose difficult issues and verify that proposed fixes will actually work. For instance, an AWS Solutions Architect SME might find that a specific configuration error in an auto-scaling group is causing performance drops.
To see how these positions differ, compare the lead roles side-by-side.
Role Comparison: Incident Manager vs. Problem Manager
The following table shows the differences in duties and skills. It illustrates how each role fits the specific goals of its discipline.
| Aspect | Incident Manager | Problem Manager |
|---|---|---|
| Primary Focus | Command and control during a live incident. | Investigation and prevention of future incidents. |
| Key Responsibility | Coordinate real-time resolution efforts. | Facilitate Root Cause Analysis (RCA). |
| Core Competency | Crisis management and rapid decision-making. | Analytical thinking and pattern recognition. |
| Measure of Success | Keeping Mean Time to Resolve (MTTR) low. | Reducing the rate of recurring incidents. |
A professional IT operation needs both of these roles to succeed. The incident management team protects the business today by keeping services running. Meanwhile, the problem management team protects the business tomorrow by ensuring those services stay stable and reliable. By separating these duties, an organization can fix immediate fires without losing sight of the underlying issues that cause them.
Measuring Success with the Right KPIs
Management teams often rely on the principle that measurement is the first step toward improvement. To determine how well your problem and incident management processes function, using the right Key Performance Indicators (KPIs) is essential. The metrics for each discipline are as distinct as their core missions.
For incident management, the central question is: "How quickly and effectively did we restore service?" This process depends on speed and efficiency while under pressure. Consequently, its KPIs reflect that urgent, reactive focus, which is often necessary for meeting SLAs and maintaining business operations.
Problem management, by contrast, asks a different question: "How successfully are we preventing future problems from occurring?" Success here is not measured in minutes. Instead, it is found in long-term stability and a real reduction in operational risk. Its KPIs track the progress toward creating a calmer, more resilient IT environment.
Incident Management KPIs: Gauging Speed and Restoration
The metrics for incident management are mostly time-based. They provide a quantitative assessment of how well the team contains damage and minimizes downtime, which correlates with user satisfaction and business continuity. These are frequently reported in IT operations and are common topics in ITIL Foundation or CompTIA Server+ exams.
Key metrics to monitor:
- Mean Time to Resolve (MTTR): This is the standard incident management KPI. It calculates the average time from an incident's logging until its complete resolution, offering a clear measure of team efficiency and restoration speed.
- First Call Resolution (FCR) Rate: This metric indicates the percentage of incidents resolved by the service desk during the initial contact without requiring escalation. A high FCR rate suggests a capable front-line team with effective tools and knowledge.
- SLA Compliance Rate: This KPI measures how often incidents are resolved within the timeframes stipulated in your Service Level Agreements. Consistently missing these targets can result in financial penalties, damage your reputation, and erode stakeholder trust.
These KPIs focus on the immediate "now." They tell a story of current operational performance, showing stakeholders how quickly the organization recovers when disruptions occur.
Problem Management KPIs: Tracking Prevention and Stability
While incident metrics emphasize speed, problem management KPIs focus on prevention and strategic improvement. These figures show your team's ability to find and eliminate the root causes of persistent, disruptive issues. The objective is to build a more stable, predictable service environment over time. This aligns with the continuous improvement principles described in ITIL.
Key Takeaway: The goal of problem management is to make itself unnecessary for a specific issue by ensuring it never happens again. Strong KPIs are how you objectively validate this long-term value.
Core KPIs for problem management include:
- Reduction in Recurring Incidents: This is the most impactful KPI. It quantifies success by tracking the decrease in incidents linked to a specific problem that has been formally solved. You can break this down by service, application, or specific infrastructure components.
- Number of Known Errors Documented: This KPI tracks new additions to your Known Error Database (KEDB). A consistent flow of entries indicates that the problem team is identifying root causes and providing workarounds for the incident team, which improves resolution efficiency.
- Root Cause Identification Success Rate: This measures the percentage of problem investigations that successfully find a verifiable root cause. A high success rate shows the team has the analytical skill needed to handle complex technical challenges.
What should IT professionals aim for? Industry benchmarks provide useful targets. High-performing organizations often achieve a MTTR under 30 minutes for critical incidents (verify current benchmarks for your specific industry). For problem management, leading organizations strive for a repeat incident rate below 2-5% and a root cause identification rate exceeding 80% (confirm these targets with your internal service level requirements). Understanding these benchmarks helps improve an organization's IT service maturity.
How They Work Together in Real Scenarios
*Caption: A video explaining the practical differences and symbiotic relationship between incident and problem management.*While the theoretical definitions of problem and incident management are important, their true value becomes clear when you see them working together. This relationship is a coordinated effort between reactive firefighting and proactive prevention. Both are necessary to maintain stable IT operations.
The following two real-world scenarios show how this partnership functions in practice. The first example covers a high-priority emergency that threatens revenue. The second example focuses on a quieter, recurring issue that might be ignored without a dedicated problem management process.
Scenario One: The Major E-Commerce Outage
It is the busiest sales day of the year for a global online retailer. At the exact moment customer traffic reaches its peak, the entire platform stops responding to requests. Monitoring systems trigger urgent alerts as internal dashboards show total service failure. Every minute of downtime costs the company thousands of dollars in lost sales and damages brand reputation.
The Incident Management Response: The incident management team begins their response immediately. Their only goal is to restore service as fast as possible.
- Communication: An Incident Manager establishes a high-priority communication channel. They bring together senior engineers and stakeholders in a virtual "war room" to coordinate the recovery effort.
- Diagnosis: Engineers quickly determine that the application servers are not responding. They suspect resource exhaustion or a critical failure in the latest code deployment.
- Workaround: The team decides that the fastest path to recovery is to reboot the primary server cluster. They also perform a rollback to the last stable version of the application.
- Resolution: Service is restored within 15 minutes (confirm recovery targets against internal service level agreements). The incident is closed. Business operations resume, which limits the total financial damage.
The incident team succeeded in stopping the immediate crisis. However, the business still does not know why the outage happened. Without further investigation, the platform remains vulnerable to the same failure during the next traffic spike.
This fast, decisive response is the definition of incident management. It contains damage to protect the business. Yet, without following up with problem management, the organization is likely to face the same disruption again.
The Problem Management Investigation: Once the sales event ends and the immediate pressure is gone, the problem management team starts their work. They open a formal problem record and link it to the major incident. Their approach is different from the incident team. It is slow, analytical, and focused on long-term stability, using methods common in ITIL Problem Management training.
- Data Collection: They examine server logs, application performance metrics, and network traffic captures from the time of the crash. They review logs from load balancers to see how traffic was distributed across the cluster.
- Correlation: They match event timestamps with recent system changes, database queries, and CPU utilization spikes.
- Root Cause Identification: After three days of analysis and collaboration with the database and development departments, the team identifies the root cause. A specific SQL query within a recently updated recommendation engine was inefficient. Under heavy user load, this query exhausted the database connection pool. This created a bottleneck that forced the application servers to stop processing requests.
With the cause identified, the team moves to a permanent solution. They work with developers to optimize the database query and reconfigure connection pool limits. They then deploy a tested patch. This change hardens the platform, ensuring it can handle high traffic without crashing. This effectively prevents the outage from happening again.
Scenario Two: The Recurring Slow Performance Complaints
This scenario involves a less dramatic but equally frustrating problem. For several weeks, the service desk has received a steady stream of tickets. Users complain that a primary internal financial application is "laggy" during the afternoon.
The Incident Management Response: For every individual ticket, the service desk analyst follows a standard troubleshooting guide:
- Client-Side Check: They ask the user to clear their browser cache, restart their computer, or check their local internet speed.
- Closure: In some cases, the slowness stops on its own. The incident ticket is closed as "user error" or a "temporary glitch."
Individually, these tickets seem minor. The service desk handles them quickly, and operational metrics look good on paper. However, a larger and more harmful pattern is being missed. User productivity is dropping, and frustration with the IT department is growing. To see how these workflows should interact at a higher level, you can explore detailed ITIL workflows in motion through MindMesh Academy's study guides.
The Problem Management Investigation: A Problem Manager who monitors incident trends identifies a recurring pattern. In the last 30 days, 15 separate incidents were logged for the same application. Every report mentioned "slowness" during a specific afternoon window. This pattern triggers a proactive problem investigation.
The problem management team starts by comparing the timestamps of every user complaint against historical monitoring data. They check logs for the application, the local network, and the underlying server infrastructure. They soon find a clear connection. The performance drop always happens at the same time as an automated, high-priority data backup.
Further research shows that the backup job was misconfigured. It was set to run with high network priority, which took up almost all the available bandwidth and CPU resources on that network segment. This throttled the application for everyone in the office.
The problem team works with the infrastructure group to move the backup to a late-night schedule. They also lower its network priority level. This permanent fix stops the "slow performance" incidents. A widespread user experience issue is solved before it could become a major system failure.
Common Questions About Incident and Problem Management
Practical application often blurs the lines between incident and problem management. In the heat of a service outage, these distinctions might feel academic, but the operational differences are significant. Addressing these frequent questions helps IT teams clarify their roles and build more reliable services.
Can an Incident Become a Problem?
Yes. This is one of the most frequent ways that problem records are generated. An incident becomes a prime candidate for a problem investigation when it meets specific criteria. Typically, this involves a major service failure with no immediately obvious cause, or a series of minor, recurring incidents that persist despite individual fixes.
This transition functions like a baton pass between two different functional goals. The incident management team focuses on speed. Their priority is to restore service and get users back to work as quickly as possible. Once the system is stable and the immediate pressure is gone, they hand the "why" over to problem management. The problem team then investigates the root cause and develops a permanent solution.
Consider a single server crash. If a technician restarts the hardware and service returns, that is an incident. However, if that same server crashes every Friday afternoon, or if a specific application shows memory leaks after every major release, you have a systemic problem. These scenarios require a detailed investigation and a long-term fix rather than a simple reboot.
Do Small Businesses Need Separate Teams?
You do not necessarily need different people to manage these two functions, but you must maintain separate processes and mindsets. In a small IT organization, it is common for a single technician to act as both the Incident Manager and the Problem Manager. The difficulty lies in knowing when to switch between these two distinct objectives.
The biggest hurdle for small teams is not a lack of staff, but a lack of dedicated time. Without a specific schedule for problem management, technicians stay trapped in a cycle of reactive firefighting. They spend their entire day treating symptoms and never have the bandwidth to address the underlying causes.
Success requires strict discipline. You must move from the fast-paced, "fix-it-now" response style of incident management to the analytical and patient approach required for root cause analysis. Even blocking out four hours each week to review the incident log and open problem records can result in better stability and higher efficiency. Identifying a single recurring hardware flaw or a software bug can save dozens of support hours in the future.
What Is a Known Error and How Does It Help?
A known error is a problem where the root cause has been identified and a temporary workaround is available, but a permanent resolution has not yet been deployed. This concept provides the most direct link between problem and incident management.
The problem management team records these findings in a Known Error Database (KEDB). This database serves as a central reference for the service desk and incident responders. When a technician encounters an incident that matches an entry in the KEDB, they do not need to begin a new troubleshooting process. They check the database, apply the proven workaround, and resolve the ticket immediately.
This practice significantly lowers the Mean Time To Resolve (MTTR) and improves user satisfaction. It allows the service desk to handle known issues efficiently while the problem management team works through the change management process to implement a permanent fix. The KEDB is a vital part of knowledge management within the ITIL framework.
Ready to master the concepts that power effective IT service management and excel in your certifications? At MindMesh Academy, we provide expert-curated study materials and evidence-based learning methods for certifications like ITIL, CompTIA, AWS, and PMP. Accelerate your career and build the skills to tackle real-world challenges by visiting ITIL 4 Foundation Practice Exams.

Written by
Alvin Varughese
Founder, MindMesh Academy
Alvin Varughese is the founder of MindMesh Academy and holds 15 professional certifications including AWS Solutions Architect Professional, Azure DevOps Engineer Expert, and ITIL 4. He's held senior engineering and architecture roles at Humana (Fortune 50) and GE Appliances. He built MindMesh Academy to share the study methods and first-principles approach that helped him pass each exam.